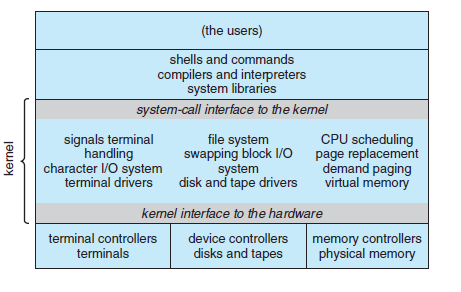
CHAPTER 6 - CPU 스케줄링(CPU Scheduling)
CH 6에서는,
- 첫째로, Multi-Programmed OS의 기반인 CPU 스케줄링에 대해서 알 수 있다.
- 둘째로, 다양한 CPU 스케줄링 알고리즘에 대해서 알 수 있다.
- 셋째로, CPU 스케줄링 알고리즘을 선택하는 평가 기준에 대해서 알 수 있다.
- 운영체제는 CPU를 프로세스들 간에 교환함으로써, 컴퓨터를 more productive으로 만든다.
- 운영체제는 사실 process가 아니라 kernel-level의 thread를 스케줄하는 것이다.
- "proess scheduling"와 "Thread scheduling"라는 용어는 서로 interchangeably 사용된다.
6.1 기본 개념(Basic Concepts)
- single-processor system에서는 한 순간에 오직 하나의 프로세스만이 실행될 수 있다.
- 나머지 프로세스들은 CPU가 free 상태가 되어, 다시 스케줄 될 수 있을 때까지 기다려야 한다.
- Multi-programming의 목적은 CPU 이용률을 최대화하기 위해 항상 실행 중인 프로세스를 갖게 하는 것이다.
- 이 방식에서, 어느 한 순간에 다수의 프로세스들을 메모리 내에 유지한다.
- 이후에 어떤 프로세스가 대기해야 하는 경우, 운영체제는 CPU를 해당 프로세스로부터 회수해서 다른 프로세스에 할당한다.
* CPU-입출력 버스트 사이클(CPU-I/O Burst Cycle)
- 프로세스 실행은 CPU 실행(CPU Execution)과 입출력 대기(I/O wait)로 구성된다.
- 프로세스들은 이들 두 상태 사이를 교대로 왔다 갔다 하며, 프로세스 실행은 CPU burst로 시작된다.
- (CPU burst, I/O burst, CPU burst, I/O burst , ...) 순으로 순차적으로 burst가 발생하게 된다.
- 마지막 CPU burst는 I/O burst가 뒤따르는 대신, 실행을 종료하기 위한 system request와 함께 끝난다.

- I/O-bound 프로그램(I/O 지향 프로그램)은 짧은 CPU burst를 가질 것이다.
- CPU-bound 프로그램(CPU 지향 프로그램)은 긴 CPU burst를 가질 것이다.
* CPU 스케줄러(CPU Scheduler)
- CPU가 idle 일 때마다, 운영체제는 ready queue에 있는 프로세스들 중에서 하나를 선택해 실행해야 한다.
- 선택은 단기 스케줄러(Short-term Scheduler, CPU scheduler)에 의해 수행된다.
- 스케줄러는 실행 준비가 되어있는 메모리 내의 프로세스들 중에서 하나를 선택하여 CPU를 할당한다.
* 선점 스케줄링(Preemptive Scheduling)
- CPU 스케줄링 결정은 아래 4가지 상황 아래에서 발생할 수 있다.
(1) 한 프로세스가 running state에서 waiting state로 전환될 때 (wait를 호출할 때)
(2) 프로세스가 running state에서 ready state로 전환될 때 (interrupt가 발생할 때)
(3) 프로세스가 waiting state에서 ready state로 전환될 때 (completion of I/O)
(4) 프로세스가 종료될 때 (When a process terminates)
- (1)과 (4)의 경우에서만 스케줄링이 발생하면 비선점(non-preemptive) 또는 협조적(Cooperative)하다.
- 비선점(non-preemptive) 스케줄링에서는, 일단 CPU가 한 프로세스에 할당되면 프로세스가 종료하든지 또는
waiting state로 전환해 CPU를 방출할 때까지 CPU를 점유한다.
- (2)와 (3)의 경우가 함께 있게 되면, 스케줄링이 선점(preemptive)형 일 수 있는데, 선점 스케줄링(Preemptive
scheduling)은 data가 다수의 프로세스에 의해 공유될 때 race condition을 발생시킬 수 있다.
* 디스패처(Dispatcher)
- CPU 스케줄링 기능에 포함된 요소들 중 하나는 디스패처(dispatcher)이다.
- 디스패처(dispatcher)는 CPU의 control을 단기 스케줄러가 선택한 프로세스에게 주는 모듈이다.
- 디스패처(dispatcher)는 아래와 같은 작업을 수행할 수 있다.
(1) 문맥을 교환하는 일(Switching context)
(2) 사용자 모드로 전환하는 일(Switching to user mode)
(3) 프로그램을 다시 시작하기 위해 user program을 적절한 위치로 이동시키는 일
(Jumping to the proper location in the user program to restart that program)
- 디스패처(dispatcher)는 모든 프로세스의 switching 시에 호출되므로, 가능한 최고로 빨리 수행되어야 한다.
- 디스패처(dispatcher)가 하나의 프로세스를 정지하고, 다른 프로세스의 수행을 시작하는 데까지 소요되는 시간을
디스패치 지연시간(dispatch latency)라고 한다.
6.2 스케줄링 기준(Scheduling Criteria)
(1) CPU 이용률(Utilization)
- 가능한 한 CPU를 최대한 바쁘게 유지시키는 것을 원할 수 있다.
- CPU 이용률(utilization)은 이론적으로 0에서 100%까지 이를 수 있다.
- 실제 시스템 상에서는 40%(부하가 적은 시스템) ~ 90%(부하가 큰 시스템)까지의 범위를 가져야 한다.
(2) 처리량(Throughput)
- 작업량 측정의 한 방법은 단위 시간당 완료된 프로세스의 개수로, 처리량(Throughput)이라고 한다.
- 처리시간이 긴 프로세스의 경우, 처리량은 시간당 한 프로세스가 될 수 있다.
- 처리시간이 짧은 프로세스의 경우, 처리량은 초당 10개의 프로세스가 될 수 있다.
(3) 총처리 시간(Turnaround time)
- 특정 프로세스의 입장에서 보면, 중요한 기준은 그 프로세스를 실행하는 데 소요되는 시간이다.
- 프로세스의 submission과 completion 사이의 interval을 총 처리 시간(Turnaround time)이라고 한다.
- 총처리 시간은 메모리에 들어가기 위해 기다리며 소비한 시간, ready queue에서 대기한 시간, CPU에서 실행한 시간,
I/O 시간을 합한 시간이다.
(4) 대기 시간(Waiting time)
- CPU 스케줄링 알고리즘은 프로세스가 ready queue에서 대기하는 시간의 양에만 영향을 준다.
- 대기 시간(Waiting time)은 ready queue에서 대기하면서 보낸 시간의 합이다.
(5) 응답 시간(Response time)
- 응답시간(Reponse time)이란, 한 request를 제출한 후, 첫 번째 response가 나올 때까지의 시간이다.
- 응답시간의 기준은 응답이 시작되는 데까지 걸리는 시간으로, 응답이 출력하는 데까지 걸리는 시간이 아니다.
- CPU utilization과 throughput을 최대화하는 것이 바람직하다.
- 총 처리시간, 대기 시간, 응답 시간을 최소화하는 것이 바람직하다.
6.3 스케줄링 알고리즘(Scheduling Algoirthm)
* 선입 선처리 스케줄링(First-Come, First Served Scheduiling, FCFS)
- 가장 간단한 CPU 스케줄링 알고리즘은 선입 선처리(FCFS) 스케줄링 알고리즘이다.
- 선입선처리(FCFS) 스케줄링 알고리즘은 비선점형(non-preemptive) 알고리즘이다.
- CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당받는 방식이다.
- 이 방법은 FIFO(First in, First out) Queue로 쉽게 관리, 구현할 수 있다.
- 이 방법의 단점은, 평균 대기 시간이 때에 따라 매우 길어질 수 있다는 점이다.
- 만약 프로세스 3개가 아래와 같을 때,
| Process | Burst time |
| P(1) | 24 ms |
| P(2) | 3 ms |
| P(3) | 3 ms |
- 프로세스가 P(1), P(2), P(3)로 도착할 때, P(1)의 대기시간은 0ms이며, P(2)는 24ms, P(3)는 27ms이다.
이에 평균 대기 시간은 (0 + 24 + 27) / 3 = 17ms이다.

- 프로세스가 P(2), P(3), P(1)로 도착할 때, P(1)의 대기시간은 6ms이며, P(2)는 0ms, P(3)는 3ms이다.
이에 평균 대기 시간은 (6 + 0 + 3) / 3 = 3ms이다.

- 이에, FCFS 방법을 사용했을 때, 평균 대기 시간은 일반적으로 최소가 아니며, 프로세스 CPU burst time이
크게 변할 경우에는 평균 대기 시간도 크게 변할 수 있다.
- 모든 다른 프로세스들이 하나의 긴 프로세스가 CPU를 양도하기를 기다리는 것을 호위효과(convoy effect)라고 한다.
- 이 효과는 짧은 프로세스들이 먼저 처리되도록 허용될 때보다 CPU와 장치 이용률이 저하되는 결과를 발생시킨다.
* 최단 작업 우선 스케줄링(Shortest-Job-First Scheduling, SJF)
- 최단 작업 우선 스케줄링(SJF) 알고리즘은 각 프로세스에 다음 CPU burst 길이를 연관시킨다.
- CPU가 available해지면, 가장 작은 next CPU burst를 가진 프로세스에게 CPU를 할당한다.
- 만약 프로세스 4개가 아래와 같을 때,
| Process | Burst time |
| P(1) | 6 ms |
| P(2) | 8 ms |
| P(3) | 7 ms |
| P(4) | 3 ms |
- SJF 알고리즘을 적용하면, P(4), P(1), P(3), P(2) 순으로 스케줄링을 하게 된다.
- P(1)의 대기시간은 3ms, P(2)의 대기시간은 16ms, P(3)의 대기시간은 9ms, P(4)의 대기시간은 0ms이다.
- 이에 평균 대기 시간은 (3 + 16 + 9 + 0) / 4 = 7ms이다.

- SJF 방식을 사용하면, 최소의 평균 시간을 가지게 할 수 있다.
- 하지만, 실제적으로 SJF를 구현할 때의 어려운 점은 다음 CPU 요청의 길이를 파악해야 한다는 점이다.
- SJF 스케줄링은 long-term scheduling에 자주 사용된다.
- short-term scheduling는 다음 CPU burst의 길이를 알 수 있는 방법이 없기 때문에, short-term scheduling
에는 사용할 수 없다.
- SJF 알고리즘은 선점형(preemptive)이거나 비선점형(Non-preemptive) 일 수 있다.
- 선점형 SJF 알고리즘은 최소 잔여 시간 우선(Shortest remaining time first) 스케줄링이라고도 불린다.
- 만약 프로세스 4개가 아래와 같을 때,
| Process | Arrive time | Burst time |
| P(1) | 0 ms | 8 ms |
| P(2) | 1 ms | 4 ms |
| P(3) | 2 ms | 9 ms |
| P(4) | 3 ms | 5 ms |
- 선점형 SJF 알고리즘의 평균 대기 시간은 ((10 - 1) + (1 - 1) + (17 - 2) + (5 - 3))/4 = 26/4 = 6.5 ms이다.

* 우선순위 스케줄링(Priority Scheduling)
- SJF 알고리즘은 일반적인 우선순위 스케줄링 알고리즘의 특별한 경우이다.
- 우선순위 스케줄링 알고리즘에서 CPU는 가장 높은 우선순위를 가진 프로세스에게 할당된다.
- 우선순위가 같은 프로세스들은 FCFS 순서로 스케줄 된다.
- 만약 프로세스 5개가 아래와 같을 때,
| Process | burst time | priority |
| P(1) | 10 ms | 3 |
| P(2) | 1 ms | 1 |
| P(3) | 2 ms | 4 |
| P(4) | 1 ms | 5 |
| P(5) | 5 ms | 2 |
- 우선순위 스케줄링을 이용하면, 아래와 같이 스케줄 된다. (평균 대기시간은 8.2ms이다.)

- 우선순위는 내부적인 요인과 외부적인 요인으로 결정된다.
- 내부적으로는 시간제한, 메모리 요구 비율 등이 있으며, 외부적으로 프로세스의 중요성, 비용 등이 있다.
- 우선순위 스케줄링은 선점형이거나 비선점형일 수 있다.
- 선점형 방식에서는 새로 도착한 프로세스의 우선순위가 현재 실행 중인 프로세스의 우선순위보다 높다면, CPU를 선점한다.
- 우선순위 스케줄링 알고리즘의 주요 문제는 indefinite blocking 또는 Starvation 문제이다.
- 우선순위 스케줄링 알고리즘을 사용할 경우, 낮은 우선순위 프로세스들이 CPU를 무한히 대기할 수도 있다.
- 이 문제를 해결하는 방법 중 하나는 노화(Aging)이다.
- 노화(Aging)는 오랫동안 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 높인다.
* 라운드 로빈 스케줄링(Round-Robin Scheduling)
- 라운드 로빈(Round-robin) 스케줄링은 특별히 time-sharing system을 위해 설계되었다.
- 이 방식에서는 시간 조각(Time Slice)라고 하는 작은 단위의 시간을 정의하여 사용한다.
- ready queue는 circular queue로 동작하며, CPU 스케줄러는 ready queue를 돌면서 한 번에 한 프로세스에게 한 번의 시간 조각(Time slice) 동안 CPU를 할당한다.
- 프로세스의 CPU burst가 한 번의 Time Slice보다 작은 경우, 실행이 끝나면 CPU를 자발적으로 방출한다.
- 프로세스의 CPU burst가 한 번의 Time Slice보다 큰 경우, Context Switch가 일어나게 되고, 실행하던 프로세스는 ready queue의 꼬리(Tail)에 넣어지게 된다.
- Round-robin 스케줄링 방식은 최적의 결과를 가져오지 않는다.
- 만약 프로세스 3개가 아래와 같을 때,
| Process | Burst time |
| P(1) | 24 ms |
| P(2) | 3 ms |
| P(3) | 3 ms |
평균 대기 시간은 17/3 = 5.66ms이다.

- Round Robin 알고리즘의 성능은 Time Slice의 크기에 매우 많은 영향을 받는다.
- Time Slice이 매우 클 때의 Round Robin 방식은 FCFS와 같아지게 된다.
- Time Slice이 매우 작을 때의 Round Robin 방식은 매우 많은 Context Switch를 발생시킨다.
- 보통 Time slice의 크기가 Context Switch 시간에 비해 더 커야 한다.
- 하지만 Time Slice의 크기가 너무 크게 되면 FCFS 방식이 되므로, CPU burst의 80%는 시간 할당량보다 짧아야 한다.
* 다단계 큐 스케줄링(Multilevel Queue Scheduling)
- 다단계 큐 스케줄링 알고리즘은 ready queue를 다수의 별도의 queue로 분류한다.
- 각 queue들은 자신의 스케줄링 알고리즘을 가지고 있을 수 있다.
- 예를 들어, foreground는 라운드 로빈 알고리즘으로 background는 FCFS에 의해 스케줄 될 수 있다.
* 다단계 피드백 큐 스케줄링(Multilevel Feedback Queue Scheduling)
- 다단계 큐 스케줄링 알고리즘은 일반적으로 프로세스들이 시스템 진입 시에 영구적으로 하나의 큐에 할당된다.
- 다단계 피드백 큐 스케줄링 알고리즘에서는 프로세스가 큐들 사이를 이동하는 것을 허용한다.
6.4 스레드 스케줄링(Thread Scheduling)
- 운영체제에서 스케줄링 되는 대상은 kernel-level threads이다.
* 경쟁 범위(Contention Scope)
- 동일한 프로세스에 속한 thread들 사이에서 CPU를 경쟁하면, 프로세스-경쟁-범위(PCS)이다.
PCS : Process-Contention Scope
- CPU 상에서 어느 kernel thread를 스케줄 할 것인지를 결정하기 위해서 kernel은
시스템-경쟁 범위(System-contention scope, SCS)를 사용한다.
6.5 다중 처리기 스케줄링(Multiple-Processor Scheduling)
- 위의 방법들은 single-processor를 가진 시스템에서 CPU를 스케줄 하는 방법에 대한 내용이다.
- 만일 여러 개의 CPU가 사용 가능하다면, 부하 공유(load sharing)이 가능하지만, 스케줄링에 어려움이 있다.
* 다중 처리기 스케줄링에 대한 접근 방법
- 비대칭 다중 처리기(Asymmetric multiprocessing)은 단지 한 processor만 시스템 자료구조를 접근하여 자료 공유의 필요성을 배제하기 때문에 간단하다.
- 대칭 다중 처리기(Symmetric multiprocessing)의 경우, 각 processor가 독자적으로 스케줄링을 한다.
* 처리기 친화성(Processor Affinity)
- 대부분의 SMP 시스템은 한 processsor에서 다른 processor의 이주를 피하고, 같은 processor에서 프로세스를 실행하고자 한다.
- 이 현상을 처리기 친화성(Processor Affinity)라고 하며, 프로세스가 현재 실행 중인 processor에 친화성을 가진다는 것을 의미한다.
- 운영체제가 동일한 processor에서 프로세스를 실행시키려고 노력하는 정책을 가지고 있지만 보장하지 않을 때,
연성 친화성(soft affinity)를 가진다고 한다. ( 이에 다른 processor로의 이주가 가능하다.)
- 몇몇 시스템은 강성 친화성(hard affinity)를 지원하는 system call을 제공한다. 이 system call을 사용하여 프로세스는 자신이 실행될 processor 집합을 명시할 수 있다.
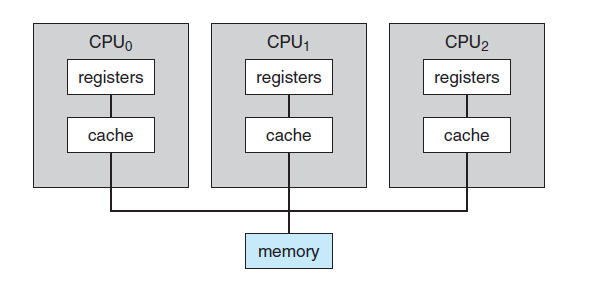
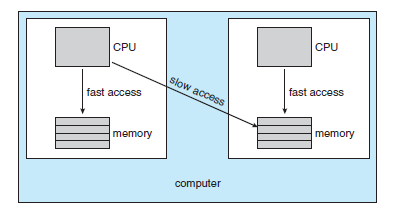
- 시스템의 main memory의 구조가 processor affinity issue에 영향을 줄 수 있다.
- 아래 그림은 NUMA(Non-uniform Memory Access) 특성을 가지는 구조를 묘사하고 있다.
* 부하 균등화(Load Balancing)
- SMP 시스템에서 processor이 하나 이상이라는 것을 최대한 활용하려면, load를 모든 processor에
균등하게 배분하는 것이 매우 중요하다.
- load balancing은 SMP 시스템의 모든 processor 사이에 load가 고르게 배분되도록 시도한다.
- load balancing에는 push migration과 pull migration이 있다.
- push migration은 과부하인 processor에서 쉬고 있는 processor로 process를 이동시킨다.
- pull migration은 쉬고 있는 processor이 바쁜 processor로 process를 pull 할 때 일어난다.
* 다중 코어 프로세서(Multicore Processor)
- 하나의 물리적인 chip 안에 여러 개의 processor core를 장착하는 구조를 multicore processor라고 한다.
- 이 방식을 사용하는 SMP 시스템은 기존 방식에 비해 속도가 빠르고 작은 전력을 소모한다.
6.6 실시간 CPU 스케줄링(Real-time CPU Scheduling)
- Real-time CPU Scheduling는 soft real-time system과 hard real-time system으로 구분된다.
- soft real-time system은 중요한 실시간 프로세스가 스케줄 되는 시점에 관해 아무런 보장도 하지 않는다.
- 이 system은 오직 중요 프로세스가 그렇지 않은 프로세스들에 비해 우선권을 가진다는 것만 보장한다.
- hard real-time system은 task는 반드시 마감시간까지 서비스를 받아야 한다.
* 지연 시간 최소화(Minimizing Latency)
- 시스템은 일반적으로 real-time으로 발생하는 event을 기다리게 된다.
- event는 software 적으로, 또는 hardware 적으로 발생할 수 있다.
- event latency는 event가 발생해서 그에 맞는 서비스가 수행될 때까지의 시간을 말한다.
- 아래의 두 가지 유형의 latency가 real-time system의 성능에 영향을 미친다.
(1) Interrupt latency (2) Dispatch latency
- interrupt latency는 CPU에 interrupt가 발생한 시점부터 해당 interrupt routine이 시작하기까지의 시간을 말한다.
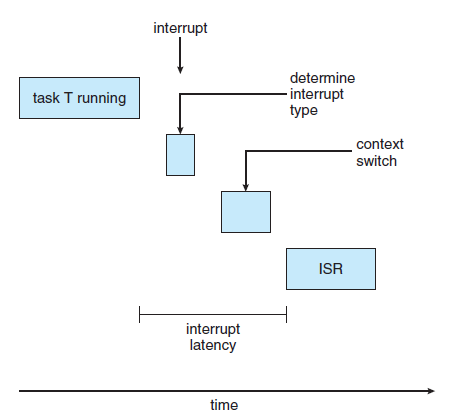
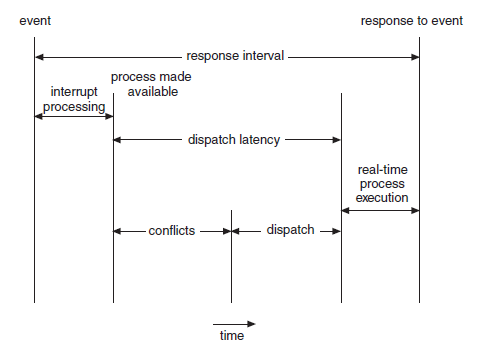
- dispatch latency는 스케줄링 dispatch가 하나의 프로세스를 블록 시키고 다른 프로세스를 시작하게 하는 데 걸리는 시간임.
* 우선순위 기반의 스케줄링(Priority-Based Scheduling)
- real-time 운영체제에서 가장 중요한 기능은 real-time 프로세스가 CPU를 필요로 할 때, 바로 응답해주는 것.
- 따라서, real-time 운영체제의 스케줄러는 선점을 이용한 우선순위 기반의 알고리즘을 제공해야 한다.
* Rate-Monotonic 스케줄링 (task의 길이가 짧은 process에게 우선순위 할당)
- Rate-Monothic 스케줄링 알고리즘은 선점 가능한 정적 우선순위 정책을 이용하여 주기 task를 스케줄 한다.
- 낮은 우선순위의 프로세스가 실행 중에 있고, 높은 우선순위의 프로세스가 실행 준비가 되면, 높은 우선순위의 프로세스가 낮은 우선순위의 프로세스를 선점한다.
- 프로세스 P(1)과 P(2)의 주기와 수행 시간이 아래와 같을 때,
| 프로세스 | 주기 | 수행 시간 |
| P(0) | 50 | 20 |
| P(1) | 100 | 35 |
- P(2)가 P(1)보다 우선순위가 높게 되면, 스케줄러는 P(1)의 마감시간을 지키지 못하게 된다. (50 < 55)
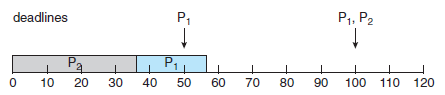
- Rate-monotonic 스케줄링을 사용하면, P(1)의 주기가 P(2)의 주기보다 짧기 때문에, P(1)의 우선순위가 P(2)의 우선순위보다 높다.

- Rate-monotonic 스케줄링 기법은 최적이기는 하지만, 많은 제약을 가지고 있다.
- CPU 이용률은 한계가 있기 때문에 CPU 자원을 최대화해서 사용하는 것은 불가능하다.
- 시스템에 한 개의 프로세스만 존재할 때, CPU 이용률은 100%이지만, 최소 69%까지 떨어지게 된다.
* Earliest-Deadline-First 스케줄링
- Earliest-Deadline-First(EDF) 스케줄링 기법은 deadline에 따라서 우선순위를 동적으로 부여한다.
- deadline이 빠를수록 우선순위는 높아지고, 늦을수록 낮아진다.
- EDF 정책에서는 프로세스가 실행 가능하게 되면 자신의 deadline을 시스템에 알려야 한다.
- 우선순위는 새로 실행 가능하게 된 프로세스의 deadline에 맞춰서 다시 조정된다.
- 이 점이 우선순위가 고정되어 있는 rate-monotonic 스케줄링 기법과 다른 점이다.
- 프로세스 P(1)과 P(2)의 주기와 수행 시간이 아래와 같을 때,
| 프로세스 | 주기 | 수행 시간 |
| P(0) | 50 | 25 |
| P(1) | 80 | 35 |
- 맨 처음, P(1)의 deadline이 P(2)보다 짧으므로 더 높은 우선순위를 가지게 되어 실행을 시작하게 된다.
그 뒤, P(1)의 실행이 끝나고 P(2)의 수행이 계속된다. (P(2)의 deadline이 P(1) 보다 짧으므로)

- EDF 알고리즘은 프로세스들이 주기적일 필요도 없고 CPU 할당 시간도 상숫값으로 정해질 필요가 없다.
- 그러나, 프로세스가 실행 가능해질 때, 자신의 deadline을 스케줄러에게 알려주어야 한다.
- 이론적으로 CPU 이용률이 100%가 될 수 있지만, 실제로는 프로세스 사이의 context switch 비용 등에 의해 100%의 CPU 이용률은 불가능하다.
* 일정 비율의 몫 스케줄링(Proportionate Share Scheduling)
- 일정 비율의 몫(Proportionate share) 스케줄러는 모든 application에게 T 개의 시간 몫을 할당하여 동작한다.
- 예를 들어, T = 100인 시간 몫이 있다고 할 때, 3개의 프로세스 A, B, C에게 각각 50, 15, 20을 할당하였다.
- 이 경우, A는 모든 processor 시간의 50%, B는 15%, C는 20%를 할당받는 것이다.
6.7 운영체제 사례들
- Linux, Windows, Solaris에서 스케줄링이 일어날 수 있다.
- Windows와 Solaris의 경우, kernel thread 스케줄링에 대해 설명하고, Linux의 경우 task 스케줄링에 대해 설명한다.
6.8 알고리즘의 평가(Algorithm Evaluation)
* 결정론적 모델링(Deterministic Modeling)
- 평가 방법의 한 중요한 부류로 분석적 평가(Analytic evaluation)가 있다.
- 분석적 평가의 한 가지 유형은 결정론적 모델링(Deterministic Modeling)이다.
- 만약 아래와 같은 작업 프로세스들이 있다고 할 때,
| 프로세스 | Burst time |
| P(1) | 10 ms |
| P(2) | 29 ms |
| P(3) | 3 ms |
| P(4) | 7 ms |
| P(5) | 12 ms |
선입 선처리(FCFS) 알고리즘의 경우, 평균 대기시간은 (0 + 10 + 39 + 42 + 49) / 5 = 28 ms이다.

비선점 SJF 알고리즘의 경우, 평균 대기시간은 (10 + 32 + 0 + 3 + 20) / 5 = 13 ms이다.

라운드 로빈(RR) 알고리즘의 경우, 평균 대기시간은 (0 + 32 + 20 + 23 + 40) / 5 = 23 ms이다.

- 이에, 위의 경우에는 SJF > RR > FCFS 순으로 평균 대기시간이 적게 든다는 것을 비교할 수 있다.
* 큐잉 모델(Queueing Models)
- 결정론적 모델을 사용할 수 있는 정적인 집합이 존재하는 경우가 드물기 때문에, 결정할 수 있는
CPU와 입출력의 분포를 사용하는 방법이다.
* 모의실험(Simulation)
- 스케줄링 알고리즘을 더욱 정확하게 평가하기 위해 모의실험(Simulation)을 사용할 수 있다.
- 모의실험을 하는 것은 컴퓨터 시스템의 모델을 프로그래밍 하는 것을 포함한다.
* 구현(Implementation)
- 스케줄링 알고리즘을 완벽히 정확하게 평가하는 유일한 방법은 실제 코드로 작성해 운영체제에 넣고
실행해 보는 것이다.
-Reference-
Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 9th』
'운영체제(OS)' 카테고리의 다른 글
| 공룡책으로 정리하는 운영체제 - CHAPTER 8. 메모리 관리 전략(Memory Management Strategies) (0) | 2022.05.08 |
|---|---|
| 공룡책으로 정리하는 운영체제 - CHAPTER 7. 교착상태(Deadlocks) (0) | 2022.05.08 |
| 공룡책으로 정리하는 운영체제 - CHAPTER 5. 프로세스 동기화(Process Synchronization) (1) | 2022.05.07 |
| 공룡책으로 정리하는 운영체제 - CHAPTER 4. 스레드(Threads) (0) | 2022.05.07 |
| 공룡책으로 정리하는 운영체제 - CHAPTER 3. 프로세스(Process) (0) | 2022.05.07 |