- 교환 정렬(Exchange Sort) : 반복문을 통해 배열의 start index부터 end index까지 한번씩 검색하는 알고리즘.
voidexchange(int n, keytype S[]){
index i, j;
for (i = 1; i <= n-1; i++)
for(j = i+1; j <= n; j++)
if(S[j] < S[i])
exchange S[i] and S[j];
}
1.2 효율적인 알고리즘 개발의 중요성
* 순차검색 대 이분검색
- 순차 검색(Sequential Search)보다 이분 검색(Binary Search)를 통해 효율적으로 Search 할 수 있다.
- 이분 검색(Binary Search) : 배열이 정렬되어 있다는 가정이 필요. 1. 찾고 싶은 수를 x라고 할 때, 배열의 정중앙에 위치한 원소 y와 비교한다. 2. 만약 x를 찾았다면, 검색을 종료한다. 3. 만약 x를 찾지 못했을 때 x가 y보다 크면 배열의 앞부분을, x가 y보다 작다면 배열의 뒷부분을 이분 검색한다.
- 따라서, 재귀함수를 사용하여 피보나치 함수를 구현하면 구하는 항의 갯수 T(n)은 아래 관계를 만족한다.
▶ 배열과 반복문을 사용하는 방법 (Dynamic Programming 기법)
- 이에 재귀함수를 사용하는 대신, 배열과 반복문을 사용하여 좀 더 효율적이게 피보나치 수를 구하는 알고리즘을 작성할 수 있다.
intfib2(int n){
index i;
int f[0..n];
f[0] = 0;
if ( n > 0) {
f[1] = 1;
for ( i = 2; i <= n; i++)
f[i] = f[i-1] + f[i-2];
}
return f[n];
}
- 이 방법은 n번째 피보나치 항을 구하기 위해서 (n+1) 개의 항을 계산한다.
1.3 알고리즘의 분석 (Analysis of Algorithms)
* 시간복잡도 분석(Complexity Analysis)
- 일반적으로 알고리즘의 실행시간은 입력의 크기가 커지면 증가하고, 총 실행시간은단위 연산이 몇 번 수행되는가에 비례한다. - 알고리즘의 시간복잡도 분석(Time Complexity Analysis)는 입력크기를 기준으로 단위 연산을 몇번 수행하는지 구하는 것이다. - 교환정렬(Exchange Sort)의 시간복잡도는,
- 크기가 n이어도, 단위 연산을 수행하는 횟수가 달라질 수 있다. (ex) 순차검색 - 이에 시간복잡도를 측정할 때, 알고리즘이 실행할 단위연산의 최대 횟수를 사용하여 최악 시간복잡도(Worst-case Time Complexity)를 구하여 사용할 수 있다. - 순차 검색(Sequential Search)의 Worst-case time Complexity W(n) = n이다.
- 알고리즘이 평균적으로 얼마나 실행하는지를 알면, 더 효율적인 경우도 존재한다. - 이 경우에는, 평균 시간복잡도(Average-case Time Complexity)를 구하여 알고리즘을 분석하는 경우가 더 합리적일 수 있다. - 평균 시간복잡도를 구하기 위해서는 n개의 입력에 확률을 각각 부여해야 한다. - 순차검색(Sequential Search)에서 찾고자 하는 수 x가 배열 S에 있는 경우는, (x가 k번째 위치에 있을 확률 : 1/n)
- 순차검색(Sequential Search)에서 찾고자 하는 수 x가 배열 S에 없는 경우에는, (x가 k번째에 위치할 확률 p/n, x가 배열에 없을 확률 1-p)
- 알고리즘이 실행할 단위연산의 최소 횟수를 통해 최선 시간복잡도(Best case Time Complexity)를 구할 수 있다 - 순차 검색(Sequential Search)의 Best-Case Time Complexity B(n) = 1이다.
1.4 차수 (Order)
- 시간복잡도(Time Complexity)가 n, 100n과 같은 경우 linear-time Algorithm 이라고 한다. - 시간복잡도(Time Complexity)가 (n^2), (0.01n^2)과 같은 경우 quadratic-time Algorithm이라고 한다.
* 차수의 직관적인 소개(An Intutive Introduction to Order)
Complexity Function의 증가율
* 차수의 정식 소개 (Rigorous Introduction to Order)
1. Big-O
- 주어진 복잡도 함수 f(n)에 대해서 O(f(n))은 정수 N 이상의 모든 n에 대해서 다음 부등식이 성립하는 양의 실수 c와 음이 아닌 정수 N이 존재하는 복잡도 함수 g(n)의 집합이다.
- Big O는 함수의 asymptotic upper bound(점근적인 상한)을 정한다.
2. Omega
- 주어진 복잡도 함수 f(n)에 대해서 Omega(f(n))은 N이상의 모든 n에 대해서 다음 부등식을 만족하는 양의 실수 c와 음이 아닌 정수 N이 존재하는 복잡도 함수 g(n)의 집합이다.
- (Big-O)와 Omega와 Theta
-Reference- Neapolitan, Richard E., 『Foundation of algorithms FIFTH EDITION』
- 중간에 데이터 삽입 및 삭제가 자주 일어날 때 사용한다. - <list> header를 include 해준 뒤에, std::list를 사용할 수 있다. - 데이터에 Random Access 하는 경우가 적을 때, 사용하는 것이 좋다. (리스트는 순차적 접근만 가능하므로) - 저장할 데이터 개수가 많거나, 검색을 자주하는 경우에는 사용하지 않는 것이 좋다. - 가변적인 길이를 가질 수 있으며, 중간에 비어있는 데이터가 존재하지 않는다.
- 많은 자료들 사이에서 검색이 용이해야 할 때 사용한다. - <map> header를 include 해준 뒤에, std::map를 사용할 수 있다. - Key와 Value는 pair 형태이다. - C++의 std::map의 경우, key를 기준으로 오름차순 정렬을 자동으로 수행한다. - 많은 데이터를 저장해야 하고, 검색이 빨라야 할 때 사용하면 좋다. - 인덱스를 사용하지 않고, iterator를 사용한다. - 중복 Key value는 사용이 불가능하다. (= 각 Key value는 unique 해야 한다.)
- map 코드 예시
#include<iostream>#include<string>#include<map>usingnamespace std;
intmain(){
// <key, value>의 pair 형태로 map을 선언함.
map<string, int> m;
// map에 데이터 삽입 (key는 중복불가, value는 중복가능)
m.insert({"ABC", 123});
m.insert({"BCD", 456});
m.insert({"CDE", 123});
// m.insert({"ABC", 789}); 는 key 중복으로 데이터 삽입이 되지 않음.// 'map iterator'를 이용하여 map에 접근할 수 있음.
map<string, int>::iterator m_iter;
for(m_iter = m.begin(); m_iter != m.end(); m_iter++)
cout << "key: " << m_iter->first << ", value: " << m_iter->second << endl;
// map에서 데이터 검색 (iterator를 반환하고, 못찾을 시 m.end()를 반환)
map<string, int>::iterator find_iter;
find_iter = m.find("ABC");
if(find_iter != m.end())
cout << "found key: " << find_iter->first << ", found value: " << find_iter->second << endl;
else
cout << "can't find data in map!" << endl;
// map에서 데이터 변경
m["ABC"] = 789;
m["BCD"] = 101112;
return0;
}
std::unordered_map (hash_map) (Key 중복 X, Value 중복 O)
- 많은 자료들 사이에서 검색이 용이해야 할 때 사용한다. - <unordered_map> header를 include 해준 뒤에, std::unordered_map를 사용할 수 있다. - Key와 Value는 pair 형태이다. - c++ std::map과 다르게, hash_map은 자동으로 정렬을 수행하지 않는다. (넣은 순서대로 데이터를 유지) - 많은 데이터를 저장해야 하고, 검색이 빨라야 할 때 사용하면 좋다. - 인덱스를 사용하지 않고, iterator를 사용한다. - 중복 Key value는 사용이 불가능하다. (= 각 Key value는 unique 해야 한다.)
- unordered_map (hash_map) 코드 예시
#include<iostream>#include<string>#include<unordered_map>usingnamespace std;
intmain(){
// <key, value>의 pair 형태로 unordered_map을 선언함.
unordered_map<string, int> um;
// unordered_map에 데이터 삽입 (key는 중복불가, value는 중복가능)
um.insert({"ABC", 123});
um.insert({"BCD", 456});
um.insert({"CDE", 789});
// um.insert({"ABC", 789}); 는 key 중복으로 데이터 삽입이 되지 않음.// 'unordered_map iterator'를 이용하여 unordered_map에 접근할 수 있음.
unordered_map<string, int>::iterator um_iter;
for (um_iter = um.begin(); um_iter != um.end(); um_iter++)
cout << "key: " << um_iter->first << ", value: " << um_iter->second << endl;
// unordered_map에서 데이터 검색 (iterator를 반환하고, 못찾을 시 m.end()를 반환)
unordered_map<string, int>::iterator find_iter;
find_iter = um.find("ABC");
if (find_iter != um.end())
cout << "found key: " << find_iter->first << ", found value: " << find_iter->second << endl;
else
cout << "can't find data in unordered_map!" << endl;
// unordered_map에서 데이터 삭제
um.erase(find_iter); // <"ABC", 123> pair 삭제// unordered_map에서 데이터 변경
um["BCD"] = 888;
um["CDE"] = 999;
return0;
}
std::set (데이터 중복 X, 순서보장 X)
- 많은 자료들 사이에서 검색이 용이해야 할 때 사용한다. - 인덱스를 사용하지 않고, iterator를 사용한다. - 중복 Key value는 사용이 불가능하다. (= 각 Key value는 unique 해야 한다.) - 이진 균형트리로 자료구조가 구성되어 있다.
- set 코드 예시
#include<iostream>#include<string>#include<set>usingnamespace std;
intmain(){
// int type의 데이터를 담는 set 선언
set<int> s;
// set에 데이터 삽입 (key는 중복불가, value는 중복가능)
s.insert(1); // s = {1}
s.insert(2); // s = {1, 2}
s.insert(3); // s = {1, 2, 3}
s.insert(4); // s = {1, 2, 3, 4}//s.insert(1); 는 key 중복으로 데이터 삽입이 되지 않음.// 'set iterator'를 이용하여 set에 접근할 수 있음.
set<int>::iterator s_iter;
for (s_iter = s.begin(); s_iter != s.end(); s_iter++)
cout << "value: " << *s_iter << endl;
// set에서 데이터 검색 (iterator를 반환하고, 못찾을 시 s.end()를 반환)
set<int>::iterator find_iter;
find_iter = s.find(1);
if (find_iter != s.end())
cout << "found value: " << *find_iter << endl;
else
cout << "can't find data in set!" << endl;
// set에서 데이터 삭제
s.erase(find_iter); // '1' value 삭제return0;
}
- c++에서는 문자열을 다루기 위해 std::string class를 사용할 수 있다. - <string> header를 include 해준 뒤에, string class를 사용할 수 있다. - 코딩테스트에서 문자열을 처리하는 문제가 빈번하게 나오니, 미리 사용법을 알아두면 좋을 것 같다.
std::string 사용법
- C++ code에서 string를 사용하기 위해서는 <string> header를 include해주어야 한다.
1. string에서의 위치 지칭 및 string의 크기 구하기 - N 크기의 길이를 가지는 string의 indexing은 0부터 N-1 까지 가능하다. - string class는 c언어의 char*(char배열)과는 달리 '\0'가 마지막에 삽입되지 않아도 된다. (예를 들어, 5크기의 길이를 가지는 string은 0~4까지의 index에 접근할 수 있다.)
2. string에서의 값 추가 및 삭제, 복사, 검색 - find()는 앞에서부터, rfind()는 뒤에서부터 검색 문자(열)을 찾아, 해당 index를 반환해준다. (못 찾았을 경우에, 'std::npos' 라는 쓰레기값을 반환해준다.)
- vector에서와 같이, string에서도 push_back()과 pop_back()이 가능하다. - string은 원하는 곳에 문자(열)을 삽입하거나 삭제할 수 있지만, 시간복잡도가 O(n)이 소요된다. - string에서 맨 뒤에 문자(열)을 삽입하는 것은 append()나 '+' operation을 사용하면 된다. - clear() 함수를 사용하면 해당 string 변수를 size가 0인 string으로 초기화 할 수 있다.
string s = "ABCDE";
int B_idx = s.find('B'); // B_index: 1int D_idx = s.rfind('DE'); // D_index: 3
s.insert(0, "123"); // s: "123ABCDE"
s.append("456"); // s: "123ABCDE456"
s = s + "FGH"; // s: "123ABCDE456FGH"
s.erase(0, 3); // s: "ABCDE456FGH" (0~2[=3-1] index 값을 삭제)
s.erase(s.find('4')); // s: "ABCDE" (index 0부터 검색하여 최초의 '4' 위치 이후의 값을 다 삭제)
s.clear(); // Initialize string variable 's'
s.push_back('F'); // s: "F"
s.push_back('G'); // s: "FG"
s.pop_back(); // s: "F"
3. string class에서의 유용한 기능들 (비교, substring, char*로의 변환) - 문자열을 비교하는 compare()는 같을 때 0, 다를 경우 -1 혹은 1을 반환한다. ([숫자 < 영어대문자 < 영어소문자] 순으로 비교를 진행하여 자신이 더 크면 1, 작으면 -1을 반환한다.)
- 'substr()'의 경우, 한개의 parameter만 입력 시 문자열의 끝부분까지 잘라서 반환한다. (만약 2개의 parameter를 입력한다면, 그 길이만큼만 잘라서 반환한다.)
- 'c_str()'을 이용하여 c++ class인 string에서 c type의 char* 로의 변환이 가능하다.
4. string을 특정 delimiter을 통해 parsing(tokenizing)하기 (1) istringstream class (delimiter가 1개일 때) - string을 parsing(tokenizing)하는 방법 중 하나로 istringstream class을 사용할 수 있다. - stringstream class는 <sstream>을 include 한 뒤에 사용할 수 있다.
#include<iostream>#include<string>#include<sstream>usingnamespace std;
intmain(){
string line = "first second third fourth";
stringstream sstream(line);
string token;
while (getline(sstream, token, ' '))
cout << token << endl;
/* output:
first
second
third
fourth
*/return0;
}
(2) find와 substr을 이용하는 방법 (delimiter가 2개 이상일 때) - string을 parsing(tokenizing)하는 방법 중 하나로 istringstream class을 사용할 수 있다. - stringstream class는 <sstream>을 include 한 뒤에 사용할 수 있다.
- 코딩테스트를 준비하다보면, 필수적으로 정렬/순열 등을 사용해야 할 때가 있다. - 이 때, <algorithm> header에 있는 함수 한 두개를 사용함으로써 위 요소들을 구현할 수 있다. - C++ code에서 Algorithm header를 사용하기 위해서는 <algorithm> header를 include 해주면 된다. - 코딩테스트 내에서는, 주로 vector container와 함께 사용되는 경우가 많다.
- 기본(default)으로는 수들을 작은 것부터 큰 것으로 정렬하는 오름차순 정렬을 수행한다. - 내림차순 정렬을 수행하기 위해서는 <functional>의 greater<int>()를 사용해야 한다. - vector를 정렬하고 싶을 땐, sort 함수의 인자로 container의 시작과 끝 iterator 값을 넣어준다. - Return value는 none이다.
- bool binary_search(ForwardIterator first, ForwardIterator last, const T& val); - 위 함수들의 인자로 (1) container의 시작과 끝 iterator 값이나 (2) array의 주소값들을 넣어준다. - 컨테이너(배열에) 찾고자 하는 값 val이 있다면 true를, 없다면 false를 반환한다.
#include<stdio.h>#include<vector>#include<algorithm>usingnamespace std;
intmain(){
vector<int> v = {10, 11, 12, 13, 14, 15, 16};
int arr[7] = {20, 21, 22, 23, 24, 25, 26};
int find_v = 14;
int find_a = 21;
if(binary_search(v.begin(), v.end(), find_v))
printf("the value %d is found in vector v!\n", find_v);
elseprintf("the value %d is not found in vector v!\n", find_v);
if (binary_search(arr, arr+7, find_a))
printf("the value %d is found in array arr!\n", find_a);
elseprintf("the value %d is not found in array arr!\n", find_a);
return0;
}
CH 9에서는, - 첫째로, 가상 메모리 시스템의 이점에 대해 알 수 있다. - 둘째로, Demand Paging과 페이지 교체 정책 등에 대해서 알 수 있다. - 셋째로, shared memory와 memory-mapping file의 관계에 대해서 알 수 있다.
- 가상 메모리라는 것은 프로세스 전체가 메모리에 올라오지 않더라도 실행이 가능하도록 하는 기법이다. - 이 기법의 주요 장점 중 하나는 사용자 프로그램이 물리 메모리보다 커져도 된다는 점이다.
9.1 배경
- 8장에서 살펴본 메모리 관리 알고리즘들은 현재 실행되고 있는 코드는 반드시 물리 메모리에 존재해야 한다. - 이 요구 조건을 만족시키는 방법은 전체 프로세스를 메모리에 올리는 것이다.
- 프로그램 전체가 한꺼번에 메모리에 올라와 있어야 하는 것은 아니라는 것을 아래 예를 보며 알 수 있다. (1) 프로그램에는 잘 발생하지 않는 오류 상황을 처리하는 코드가 존재한다. 이 코드는 거의 실행되지 않는다. (2) 배열, 리스트, 테이블 등은 필요 이상으로 많은 공간을 점유할 수 있다. (3) 프로그램 내의 어떤 옵션이나 기능들은 거의 사용되지 않는다.
- 만약 프로그램을 일부분만 메모리에 올려놓고 실행할 수 있다면, 다음과 같은 장점들이 있다. (1) 프로그램이 물리 메모리 크기에 의해 제약받지 않게 된다. (2) 각 사용자 프로그램이 더 작은 메모리를 차지하므로, 더 많은 프로그램을 수행할 수 있게 된다. (3) 프로그램을 메모리에 올리고, 스왑하는데 필요한 입출력 횟수가 줄어들어서 프로그램이 보다 빨리 실행된다.
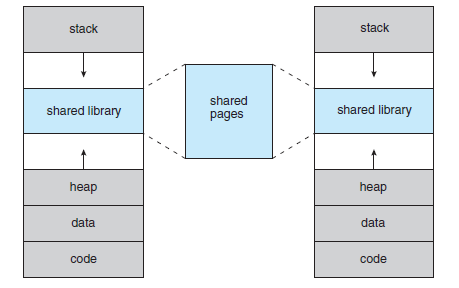
- 논리 메모리를 물리 메모리부터 분리시켜주는 것 외에 가상 메모리는 페이지 공유를 통해 파일이나 메모리가 둘 또는 그 이상의 프로세스들에 의해 공유되는 것을 가능하게 한다. 이는 아래와 같은 장점들이 있다. (1) 시스템 라이브러리가 여러 프로세스들에 의해 공유될 수 있다. (2) 프로세스들이 메모리를 공유할 수 있다.
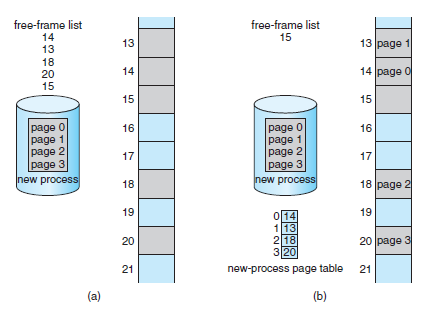
9.2 요구 페이징(Demand Paging)
- 프로그램을 디스크에서 메모리로 load 하는 가장 간단한 방법은 프로그램 시작 시에 프로그램의 전부를 물리 메모리에 load 하는 것이다. - 다른 방법으로는 초기에 필요한 것들만 메모리에 load 하는 요구 페이징(Demand Paging) 전략이 있을 수 있다. - Demand Paging을 사용하는 가상 메모리에서는 페이지들이 실행 과정에서 필요로 할 때 load 된다.
- Demand Paging 기법은 프로세스를 실행하고 싶으면 메모리로 읽어들인다 (Swap in) - 이때, 전체 프로세스를 읽어오지 않고, 필요하지 않은 페이지는 메모리에 load 하지 않는다. - 이 역할을 게으른 스와퍼(Lazy Swapper) 또는 페이저(Pager)가 수행한다. - 페이저(Pager)는 프로세스 내의 개별 페이지들을 관리한다.
* 기본 개념(Basic Concept)
- Swap-in 시에 Pager는 프로세스가 swap-out 되기 전에 실제로 사용될 페이지들이 어떤 것인지를 추측한다. - Pager는 프로세스 전체를 swap-in 하는 대신에 실제 필요한 페이지들만 메모리로 읽어온다. - 사용되지 않을 페이지를 메모리에 가져오지 않음으로써 시간과 메모리 낭비를 줄일 수 있다.
디스크 내 인접한 공간과 페이지화된 메모리 간의 이동
- 이를 위해 8.4.3절에서 언급한 valid/invalid bit를 사용할 수 있다. - Demand Paging에서 이 비트가 valid 하면, 해당 페이지가 메모리에 있다는 의미이다. - Demand Paging에서 이 비트가 invalid 하면, 해당 페이지가 유효하지 않거나, 디스크에 존재한다는 의미이다.
일부 페이지가 주 메모리에 없을 때의 페이지 테이블
- 만약 프로세스가 메모리에 올라와 있지 않은 페이지를 접근하려고 하면, 페이지 부재 트립(Page-fault trap)이 발생한다.
- 페이지가 적재되고 나면 프로세스는 수행을 계속하는데, 프로세스가 사용하는 모든 페이지가 메모리에 올라올 때까지 필요할 때마다 페이지 부재(Page Fault)가 발생한다. 이후, 일단 필요한 모든 페이지가 load 되고 나면, 더 이상 fault는 발생하지 않는다.
- 이는 어떤 페이지가 필요해지기 전에는 해당 페이지를 메모리로 적재하지 않는 "pure demand paging"이다.
- 프로그램들은 한 명령어에서도 여러 page fault를 일으킬 가능성이 있지만, 실제 프로그램들은 어느 한 특정
작은 부분만 집중적으로 참조하는 경향이 있기 때문에, demand paging은 만족할만한 성능을 보인다.
* 요구 페이징의 성능(Performance of Demand Paging)
- page fault의 확률이 p라고 하면, 실질 접근 시간(Effective access time)은
- Page fault를 처리하는 시간은 아래 3가지의 큰 요소로 이루어져 있다. 1. 인터럽트의 처리 (Service the page-fault interrupt.) 2. 페이지 읽기 (Read in Page) 3. 프로세스 재시작 (Restart the process.)
- 실질 접근 시간(Effective access time) 페이지 부재율(Page fault rate)에 비례한다. - 이에 페이지 부재율(Page fault rate)를 낮추는 것이 성능을 높이는 데 중요하다.
- Demand Paging의 또 다른 특성 중 하나는 스왑 공간의 관리이다. - 스왑 공간에서의 디스크 입출력은 일반적인 파일 시스템에서의 입출력보다 빠르다. - 그 이유는 스왑 공간은 파일 시스템보다 더 큰 블록을 사용하기 때문이고, 또 스왑공간과 입출력을 할 때는 lookup이나 간접 할당 방법 등은 사용하지 않기 때문이다.
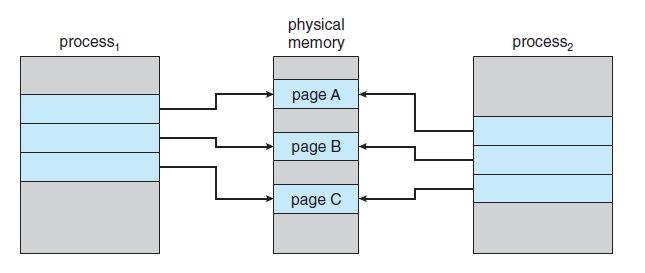
9.3 쓰기 시 복사(Copy-on-write)
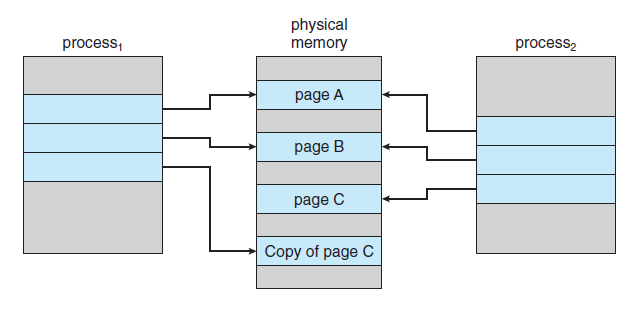
- fork() 이후 exec()를 호출할 자식 프로세스에서는 부모로부터 복사해온 페이지들은 다 쓸모가 없어진다. - 이에, 부모의 페이지들을 다 복사해오는 대신 쓰기 시 복사(copy-on-write) 방식을 사용할 수 있다. - 이 방식에서는 자식 프로세스가 시작할 때 부모의 페이지를 당분간 함께 사용하도록 한다. - 이때, 공유되는 페이지를 쓰기 시 복사(copy-on-write) 페이지라고 표시하며, "두 프로세스 중 한 프로세스가 공유 중인 페이지에 쓸 때 그 페이지의 복사본이 만들어진다."라는 의미이다. - 수정되지 않는 페이지들은 자식과 부모 간에 계속 공유 될 수 있는 것이다.
프로세스 1이 페이지 C를 수정하기 전
프로세스 1이 페이지 C를 수정하기 후
- copy-on-write 처리 과정에서 페이지 복사본을 만들 때, 보통 OS는 zero-fill-on-demand 기법을 사용한다. - zero-fill-on-demand 기법에서는 페이지를 할당할 때 그 내용을 다 0으로 채워 이전 내용을 지우게 된다.
9.4 페이지 교체(Page Replacement)
* 기본적인 페이지 교체
- 페이지 교체(Page Replacement)는 아래와 같이 행해진다. (1) 만약 빈 frame이 없다면, 현재 사용되고 있지 않은 프레임을 찾아서 비운다. (2) 해당 프레임의 내용을 swap space에 쓰고, 페이지 테이블을 변화시킨다. (프레임이 비어있음을 나타냄) (3) 비워진 프레임을 page fault를 발생시킨 프로세스에게 할당하여 사용한다.
- 빈 frame이 없는 경우에 디스크를 두 번 접근해야 하므로 page fault service time이 2배 소요된다. - 이러한 overhead는 modify bit 또는 dirty bit를 사용해서 감소시킬 수 있다.
- Demand Paging 시스템은 아래 두 가지 중요한 문제를 해결해야 한다. (1) 프레임 할당 알고리즘(Frame Allocation Algorithm) (2) 페이지 교체 알고리즘(Page-replacement Algorithm) - 즉, 각 프로세스에게 얼마나 많은 frame을 할당해야 하는지와 어떤 page를 교체해야 하는지를 결정해야 한다. - 일반적으로, page-fault rate가 가장 낮은 페이지를 선정하여 교체한다.
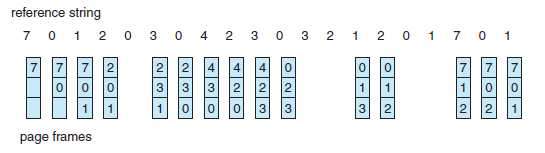
- 이후 설명할 페이지 교체 알고리즘의 설명을 위해 3개의 프레임을 가진 메모리를 가정하고, page reference string은 아래와 같다.
- 가장 간단한 페이지 교체 알고리즘은 FIFO(First in, First out) 알고리즘이다. - 메모리에 가장 오래 올라와 있던 page를 바꾸는 방법이다. - 예시 page reference string에 대해 15개의 page fault를 일으킨다.
FIFO Page Replacement Algorithm
- FIFO 알고리즘은 성능이 항상 좋지 않은데, 아래와 같은 경우에 그렇다.
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
- 이 경우, 4개의 frame을 사용하면 page fault가 10번, 3개의 frame을 사용하면 page fault가 9번 일어난다. - 이러한 결과는 모순적이며, 이를 Belady의 모순(Belady's anomaly)라고 부른다. - Belady의 모순은 프로세스에게 frame을 더 주었음에도, page fault가 더 증가하는 것을 의미한다.
* 최적 페이지 교체(Optimal Page Replacement)
- 최적 교체 정책(Optimal page replacement algorithm)은 항상 최적의 결과를 가져온다. - 이 정책은 "앞으로 가장 오랫동안 사용되지 않을 페이지를 찾아 교체"하는 방법이다. - 이 알고리즘은 할당된 frame 수가 고정된 경우, 가장 낮은 page fault rate를 보장한다. - 예시 page reference string에 대해 9개의 page fault를 일으킨다.
Optimal Page Replacement algorithm
- 하지만, 실제로 최적 페이지 교체 알고리즘은 구현하기 힘들다. - 이 방식은 프로세스가 메모리를 앞으로 어떻게 참조할 것인지를 미리 알아야 하기 때문이다.
* LRU 페이지 교체(LRU Page Replacement)
- LRU(Least Recently Used) 페이지 교체 알고리즘은 최근의 과거를 가까운 미래의 근사치로 보는 알고리즘이다. - LRU는 각 페이지마다 마지막 사용 시간을 유지하고, 페이지 교체 시에 가장 오랫동안 사용되지 않은 페이지를 교체한다. - 예시 page reference string에 대해 12개의 page fault를 일으킨다.
LRU Page Replacment Algorithm
- LRU 알고리즘은 페이지 교체 알고리즘으로 자주 사용되며, 좋은 알고리즘으로 인정받고 있다. - 하지만, 이 알고리즘을 구현하기 위해서는 하드웨어의 지원이 필요하며, 아래 두 가지 방법이 가능하다. (1) 계수기(Counters) : 각 페이지 항목마다 time-of-use field를 넣는다. (2) 스택(stack) : 페이지 번호에 대한 스택을 유지하여, top이 가장 최근, bottom이 가장 오래된 페이지가 된다.
* LRU 근사 페이지 교체(LRU Approximation Page Replacement)
- LRU page replacement를 충분히 지원할 수 있는 하드웨어는 거의 없다. - 그러나, 많은 시스템들이 참조 비트(Reference bit)의 형태로 어느 정도의 지원을 하려고 한다. - 처음에 모든 참조 비트는 0으로 초기화 고, 프로세스가 실행되면서 참조되는 페이지의 비트는 1로 바뀐다.
(1) 부가적 참조 비트 알고리즘(Additional-Reference Bits Algorithm) - 일정한 간격마다 참조 비트를 기록함으로써 추가적인 선후 관계 정보를 얻을 수 있다. - 각 페이지에 대해 8비트의 참조 비트를 사용하며, 가장 최근 8구간 동안의 해당 페이지의 사용 기록을 담는다.
(2) 2차 기회 알고리즘(Second-Chance Algorithm) - 2차 기회 알고리즘의 기본은 FIFO 교체 알고리즘이다. 이와 함께 페이지가 선택될 때마다 참조 비트를 확인한다. - 참조 비트가 0이면 페이지를 교체하고, 1이면 다시 한번 기회를 준 뒤 FIFO로 넘어간다.
(3) 개선된 2차 기회 알고리즘(Enhanced Second-Chance Algorithm) (0, 0) : 최근에 사용되지도 변경되지도 않은 경우 (교체하기 가장 좋은 페이지) (0, 1) : 최근에 사용되지는 않았지만, 변경은 된 경우 ( 교체에 적당하지 않은 페이지) (1, 0) : 최근에 사용은 되었으나, 변경은 되지 않은 경우 ( 다시 사용될 가능성이 높은 페이지) (1, 1) : 최근에 사용도 되었고, 변경도 된 경우 (다시 사용될 가능성이 높으며 교체에 적당하지 않은 페이지)
* 계수 기반 페이지 교체(Counting-Based Page Replacement)
- 아래 두 가지 기법이 있다. (1) LFU (Least Frequently Used) : 참조 횟수가 가장 작은 페이지를 교체하는 알고리즘 (2) MFU (Most Frequently Used) : 참조 횟수가 가장 큰 페이지를 교체하는 알고리즘
- 이 두 가지 알고리즘은 구현하는 데 비용이 많이 들고, OPT 알고리즘을 근사하지 못하기 때문에 잘 쓰이지 않는다.
* 페이지 버퍼링 알고리즘(Page-Buffering Algorithm)
- 페이지 교체 알고리즘과 병행하여 여러 가지 버퍼링 기법이 사용될 수 있다.
(1) 시스템이 available frame을 여러 개 가지고 있다가, page fault가 발생하면 교체될 페이지를 기다리지 않고 새로운 페이지에 먼저 읽어 들이게 하는 방법
(2) available frame pool을 유지하지만, 그 pool 속 각 frame의 원래 임자 페이지가 누구였었는지를 기억하는 방법
9.5 프레임의 할당(Allocation of Frames)
- 여러 개의 프로세스들에 대해 제한된 메모리를 어떻게 할당할 것인가에 대한 문제이다.
* 최소로 할당해야 할 프레임의 수 (Minimum Number of Frames)
- 페이지 공유가 없다면, avilable frame 수보다 더 많이 할당할 수는 없지만, 너무 작게 할당해서는 안 된다. - 각 프로세스에 할당되는 frame 수가 줄어들면 page fault rate는 증가하고, 프로세스 실행은 늦어지게 된다.
* 할당 알고리즘(Allocation of Algorithms)
- 가장 쉬운 할당 방법은 모든 프로세스에게 똑같이 할당해 주는 방법이다. - 예를 들어 93개의 frame과 5개의 프로세스가 있을 경우, 각 프로세스는 18개의 frame을 할당받는다. - 나머지 3개의 frame은 free frame buffer pool로 활용한다. - 이런 방법을 균등 할당(Equal Allocation)이라고 한다.
- 그러나, 10KB와 132KB의 프로세스가 있을 경우, 균등 할당은 좋은 방법이 아니다. - 이에, 각 프로세스의 크기 비율에 맞춰 frame을 할당하는 비례 할당 방식(Proportional allocation)을 사용할 수 있다. - 균등 할당과 비례 할당은 모두 프로세스의 우선순위를 고려하지 않는 방법이다.
* 전역 대 지역할당(Global Veersus Local Allocation)
- 다수의 프로세스가 frame 할당을 위해 경쟁하는 환경에서 페이지 교체 알고리즘은 크게 두 가지 범주로 나뉜다. (1) 전역 교체(Global Replacement) (2) 지역 교체 (Local Replacement)
- 전역 교체는 프로세스가 교체할 frame을 다른 프로세스에 속한 frame을 포함한 모든 프레임을 대상으로 찾는 경우이다. - 지역 교체는 각 프로세스가 자기에게 할당된 frame들 중에서만 교체될 victim을 선택할 수 있는 경우이다.
- 지역 교체 방법에서는 프로세스에 할당된 프레임의 수는 변하지 않는다. - 전역 교체 아래에서는 한 프로세스에 할당된 프레임의 수는 바뀔 수 있다.
- 전역 교체 알고리즘에서의 한 가지 문제점은 한 프로세스가 그 자신의 page fault rate를 조절할 수 없다는 것. - 한 프로세스의 page fault rate는 그 프로세스가 어떤 프로세스들과 함께 실행되느냐에 영향을 받는다. - 지역 교체 알고리즘의 경우는 다른 프로세스에게 영향을 받지 않는데, 유일하게 그 프로세스의 페이징 형태에만 영향을 받기 때문
- 일반적으로 전역 교체가 지역 교체 알고리즘보다 더 좋은 성능을 보이며, 더 자주 쓰인다.
* 비균등 메모리 접근(Non-Uniform Memory Access)
- 메모리 접근 시간이 현저하게 차이가 나는 시스템을 모두 비균등 메모리 접근(NUMA)라고 한다. - 이러한 시스템에서 메모리를 동등하게 대하면, NUMA 구조를 고려한 메모리 할당 알고리즘을 사용하는 시스템에서보다 CPU가 메모리를 접근할 때 대기 시간이 매우 길어지게 된다.
9.6 스레싱(Thrashing)
- 충분한 frame을 할당받지 못한 프로세스는 page fault가 바로 발생하게 된다. - 이미 활발하게 사용되는 페이지들로만 이루어져 있으므로, 어떤 페이지가 교체되든 바로 다시 필요해진다. - 이런 과도한 페이징 작업을 스레싱(Thrashing)이라고 한다.
* 스레싱의 원인(Cause of Thrashing)
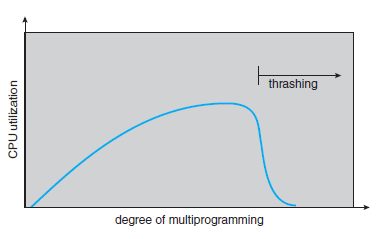
- 스레싱(Thrashing)은 심각한 성능 저하를 유발한다. - 운영체제는 CPU 이용률(Utilization)을 검사하게 되는 데, 만약 CPU 이용률이 너무 낮아지면 새로운 프로세스를 시스템에 더 추가해서 다중 프로그래밍의 정도(Degree)를 높인다.
- 만약 많은 프로세스들이 실행을 위해 추가의 프레임을 원한다면, 계속해서 page fault가 발생할 것이다. - 이에 따라, 프로세스들이 paging device를 기다리는 동안 CPU 이용률은 계속해서 떨어진다. - CPU 스케줄러는 CPU 이용률이 떨어지는 것을 보고, 계속 새로운 프로세스를 추가하려고 할 것이다. - 계속해서 더 많은 page fault와 더 긴 pageing device waiting time이 생기게 된다. - 이에 스레싱(Thrashing)이 발생하게 되고, 시스템의 처리율이 상당히 낮아지게 된다.
- 다중 프로그래밍의 정도가 높아짐에 따라, 계속해서 CPU 이용률이 최댓값까지 증가하기는 한다. - 하지만, 그 뒤 급격하게 감소하며 스레싱(Thrashing)이 이 일어나게 된다. - 따라서 최고점에서 다중 프로그래밍의 정도를 낮춰야 한다.
- 스레싱(Thrashing)은 지역 교환 알고리즘이나 우선순위 교환 알고리즘을 사용하면 제한할 수 있다. - 지역 교환 알고리즘을 사용하면, 한 프로세스가 스레싱을 유발하더라도 다른 프로세스로부터 frame을 뺏어올 수 없으므로, 다른 프로세스는 스레싱(Thrashing)으로부터 자유로울 수 있다.
- 스레싱(Thrashing) 현상을 방지하기 위해서는 각 프로세스가 필요로 하는 최소한의 프레임 개수를 보장해야 한다. - 프로세스가 실제로 사용하고 있는 프레임의 수가 몇 개인가를 알아보는 것은 프로세스 실행의 지역성 모델(Locality model)을 기반으로 한다. - 지역성 모델이란 프로세스가 실행될 때에는 항상 어떤 특정한 지역에서만 메모리를 집중적으로 참조함을 말한다.
* 작업 집합 모델(Working-Set Model)
- 작업 집합 모델(Working-Set Model)은 지역성을 기반으로 하고 있다. - 기본 아이디어는 최근 △만큼의 page reference를 관찰하겠다는 것이다. - 한 프로세스가 최근 △번 페이지를 참조했다면, 그 안에 들어있는 서로 다른 페이지들의 집합을 작업 집합이라고 부른다.
* 페이지 부재 빈도(PFF, Page-Fault Frequency)
- 작업 집합 모델은 성능이 좋으며, 작업 집합에 대해 안다는 것은 선페이징(prepaging) 시에 유용하다. - 하지만 스레싱을 조절하는 데는 알맞지 않을 수 있는데, 페이지 부재 빈도(PFF)는 보다 더 직접적으로 스레싱(Thrashing)을 조절한다.
- 스레싱(Thrashing)이란 페이지 부재율(Page Fault rate)이 높은 것을 의미한다. - 페이지 부재율이 너무 높으면 그 프로세스가 더 많은 Frame을 필요로 한다는 의미이다. - 페이지 부재율이 너무 낮으면 그 프로세스가 너무 많은 Frame을 갖고 있다는 것을 의미한다. - 따라서 페이지 부재율의 상한과 하한을 정해놓고, 만약 페이지 부재율이 상한을 넘으면 그 프로세스에게 Frame을 더 할당해 주고, 하한보다 낮아지면 그 프로세스의 프레임 수를 줄인다. - 위의 방법으로 직접적으로 부재율을 관찰하고 조절함으로써 스레싱(Thrashing)을 방지할 수 있다.
9.7 메모리 사상 파일(Memory-Mapped File)
- open(), write() system call을 사용하여 디스크에 있는 파일을 순차적으로 읽는다고 가정해보자.
- 이러한 방식을 사용하면 파일이 매번 access 될 때마다, system call을 해야 한다.
- 이와 같이 하는 대신에 디스크 입출력을 메모리 참조 방식으로 대신할 수 있다.
- 이러한 방식을 메모리 사상(memory-mapping)이라고 한다.
9.8 커널 메모리의 할당
- 커널 메모리는 보통 사용자 모드 프로세스에게 할당해 주기 위한 페이지 리스트와는 별도의 메모리 풀에서 할당받는다. 그 이유는 아래 2가지와 같다.
(1) 커널은 다양한 크기의 자료 구조를 위해 메모리를 할당받는다. 이 자료구조들은 페이지 크기보다 작은 크기를 갖기도 한다. 때문에 커널은 메모리를 조심스럽게 사용하여야 하고, 단편화에 의한 낭비를 줄여야 한다.
(2) 사용자 모드 프로세스에 할당되는 페이지는 물리 메모리 상에서 꼭 연속적일 필요가 없다. 하지만, 특정 하드웨어 장치는 물리적으로 연속적인 메모리를 요구할 수 있다.
* 버디 시스템
- 버디 시스템은 물리적으로 연속된 페이지들로 이루어진 고정된 크기의 세그먼트로부터 메모리를 할당한다.
- 메모리는 이 세그먼트로부터 2의 거듭제곱 단위로 할당된다.
- 예를 들어 11KB가 요청되면, 16-KB 세그먼트가 할당된다.
- 버디 시스템의 장점 중 하나는 합병(Coalescing)라고 부르는 과정을 통해 서로 인접한 버디들이 손쉽게 하나의 큰 세그먼트로 합쳐질 수 있다는 점이다.
- 버디 시스템의 분명한 단점은 2의 거듭제곱 단위로 메모리를 할당받기 때문에, 단편화를 불러올 수 있다.
Buddy System Allocation
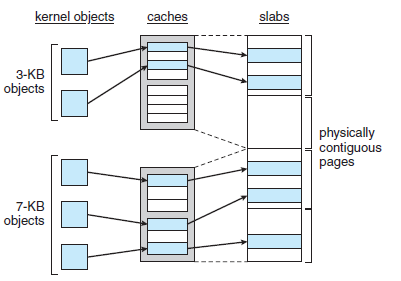
* 슬랩 할당(Slab Allocation)
- 두 번째 커널 메모리 할당 정책은 슬랩 할당(Slab Allocation)이다.
- 슬랩(Slab)은 하나 이상의 연속된 페이지들로 구성되어 있으며, 캐시(Cache)는 하나 이상의 슬랩들로 구성된다.
Slab Allocation
9.9 기타 고려 사항
* 프리 페이징(PrePaging)
- 프리 페이징(prepaging)는 과도한 페이지 부재를 방지하기 위한 기법이다. - 프리 페이징(prepaging)은 관련된 모든 페이지를 사전에 한꺼번에 메모리 내로 가져오는 기법이다. - 프리 페이징(prepaging)을 하는 이유는 미리 올라온 페이지들이 실제로 곧 사용될 것이라고 예상하기 때문이다.
* 페이지 크기(Page Size)
- 페이지 테이블의 크기를 작게 유지하기 위해서는 큰 크기의 페이지가 좋다. - 할당해 준 메모리 사용 효율을 높이기 위해서는 작은 크기의 페이지가 좋다. (내부 단편화를 줄임)
* 역 페이지 테이블(Inverted Page Table)
- 8.6.3절에서 역 페이지 테이블의 목적은 페이지 테이블이 차지하는 메모리 공간을 줄이기 위함이었다. - 이 테이블은 <process-id, page-number>의해 index 되며, 물리 메모리마다 한 항목을 갖는다. - 각 페이지 프레임에 어떤 가상 메모리 페이지가 저장되어 있는지의 정보만 유지하면 되기 때문에 필요한 물리 메모리 양을 줄인다.
- 이 밖에도 프로그램 구조, 입출력 상호 잠금과 페이지 잠금 등을 고려해야 한다.
-Reference- Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 9th』
CHAPTER 8 - 메모리 관리 전략(Memory Management Strategies)
CH 8에서는, - 첫째로, Memory Hardware를 구성하는 다양한 방법에 대해 알 수 있다. - 둘째로, 프로세스에게 Memory를 할당하는 다양한 기법들에 대해 알 수 있다. - 셋째로, 현대 컴퓨터 시스템의 Paging의 동작 방법에 대해서 알 수 있다.
- 성능을 향상시키기 위해서는 여러 프로세스들이 주 메모리(Main Memory)를 공유해야 한다. - 메모리를 관리하는 방법은 단순 hardware 방식에서 paging, segment 방법까지 다양하게 존재한다.
8.1 배경(Background)
- Memory는 각각 주소가 할당된 byte들의 array로 구성된다.
* 기본 하드웨어
- Main Memory와 processor 자체에 내장되어 있는 register들은 CPU가 직접 접근할 수 있는 유일 general-purpose storage이다. - 따라서, 모든 실행되는 instruction과 data들은 CPU가 직접적으로 접근할 수 있는 main memory와 register에 있어야 한다.
- CPU에 내장되어 있는 register들은 일반적으로 CPU clock의 1 cycle 내에 접근이 가능하다. - 대부분의 CPU들은 register에 있는 instruction의 decode와 간단한 operation을 이 시간 내에 처리한다.
- memory bus를 통해 전송되는 main memory의 경우, main memory에 대한 접근을 완료하기 위해서는 많은 CPU clock tick cycle이 소요되며, 이 경우 CPU가 필요한 데이터가 없어서 명령어를 수행하지 못하고, 지연(Stall) 되는 현상이 발생하게 된다. - 이 문제를 해결하기 위해 CPU와 main memory 사이에 빠른 속도를 가진 Cache를 추가하는 것이다. - Cache는 보통 빠르게 접근할 수 있도록 하기 위해 CPU 안에 있으며, Memory 접근 속도를 향상시킨다.
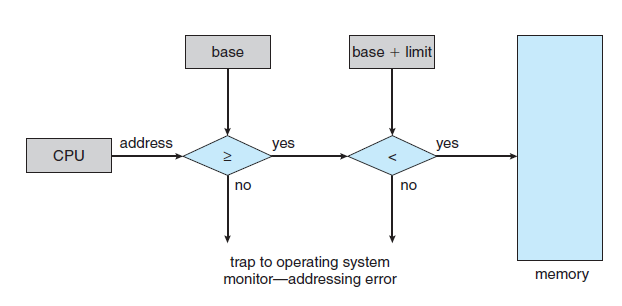
- 시스템이 올바르게 동작하기 위해서는 운영체제 영역을 보호해야 하며, Multi-user System인 경우 추가적으로 다른 user program이 특정 user program을 접근하는 것을 막아야 한다. - OS가 이를 행하면 성능이 떨어지기 때문에, hardware가 이를 지원해야 한다. - base와 limit register를 사용하여 Memory 보호 기법을 제공할 수 있다.
* 주소의 할당
- 프로그램은 원래 binary executable file로 disk에 저장되어 있어야 한다. - 프로그램이 "Main Memory"로 올라오게 되면, 프로세스가 되어야 한다. - 디스크에서 Main Memory로 들어오기를 기다리고 있는 프로세스들의 집합은 input queue를 구성한다.
- 보통 single-tasking의 작업 절차는 input queue의 프로세스 중 하나를 선택해서, Memory로 load 한다. - 이 프로세스가 종료되면, 해당 프로세스가 사용했던 memory space가 available space가 된다.
- 대부분의 시스템은 user 프로세스가 memory 내 어느 부분으로도 올라올 수 있도록 지원한다. - 대부분의 경우 user pgoram은 아래 그림과 같이 여러 단계를 거쳐 실행되기 때문에 이들 단계를 거치는 동안 주소들은 여러 가지 다른 표현 방식을 거치게 된다.
- 전통적으로 Memory 주소 공간에서 instruction과 data의 binding은 그 binding이 이루어지는 시점에 따라 다음과 같이 구분된다.
(1) 컴파일 시간(Compile time) 바인딩 : 만일 프로세스가 memory 내에 들어갈 위치를 컴파일 시간에 미리 알 수 있으면 컴파일러는 absolute code를 생성할 수 있다.
(2) 적재 시간(Load time) 바인딩 : 만약 프로세스가 memory 내 어디로 올라오게 될지를 compile 시점에 알지 못하면, 컴파일러는 일단 이진 코드를 relocatable code로 만들어야 한다.
(3) 실행 시간(Execution time) 바인딩 : 만약 프로세스가 실행하는 중간에 Memory 내의 한 세그먼트로부터 다른 세그먼트로 옮겨질 수 있다면, "바인딩이 실행 시간까지 허용되었다"라고 한다.
* 논리 대 물리 주소 공간(Logical-Versus Physical-Address Space)
- CPU가 생성하는 주소를 논리 주소(Logical Address)라고 하며, memory가 취급하게 되는 주소를 일반적으로 물리 주소(Physical Address)라고 한다. - 앞의 binding 분류에서 compile time과 load time의 bind은 논리 주소와 물리 주소가 같다. - Execution time의 binding의 경우 논리 주소를 가상 주소(Virtual Address)라고 한다.
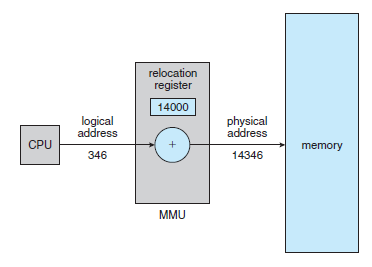
- 프로그램의 실행 중에는 가상 주소를 물리 주소로 바꿔주어야 하는데, 이 변환 작업은 hardware인 MMU(Memory Management Unit)에 의해 실행된다. - base register는 relocation register라고도 불린다.
- 만약, relocation register 값이 14000이라면, 346번지를 access 할 때, 실은 14346 번지를 access 하게 된다. - 이에, user program은 실제적인 물리 주소(Physical Address)를 절대 알 수 없다. - 단지 346번지에 대한 pointer를 생성해서 그것에 대한 저장, 연산, 비교 등의 작업을 수행할 수 있다.
* 동적 적재(Dynamic Loading)
- 지금까지 프로세스가 실행되기 위해서는 그 프로세스 전체가 미리 memory에 올라와 있어야 했다. - 이 경우, 프로세스의 크기는 memory의 크기보다 커서는 안 된다.
- 이에, memory 공간의 보다 효율적인 이용을 위해서는 동적 적재(Dynamic Loading)이 필요하다. - 동적 적재(Dyanmic Loading)의 장점은 Routine이 필요한 경우에만 적재되는 것이다. - 이러한 구조는 오류 처리 루틴과 같이 아주 간혹 발생하면서도 많은 양의 코드를 필요로 하는 경우에 유용하다.
* 동적 연결 및 공유 라이브러리(Dynamic Linking & Shared Libaries)
- 동적 연결 라이브러리(Dynamically linked libraries)는 사용자 프로그램이 실행될 때, 해당 프로그램에 연결되는 시스템 라이브러리이다.
- 동적 연결에서는 library를 부르는 곳마다 stub이 생기게 된다. (stub : 라이브러리를 어떻게 찾을 것인가에 대해 알려주는 small code piece)
8.2 스와핑(Swapping)
- 프로세스가 실행되기 위해서는 memory에 있어야 하지만, 프로세스는 실행 중에 임시로 예비 저장 장치(backup store)로 내보내어졌다가 실행을 계속하기 위해 다시 Memory로 되돌아올 수 있다.
- 모든 프로세스의 물리 주소 공간 크기의 총합이 시스템의 실제 물리 memory 크기보다 큰 경우에도 swapping을 사용하면, 동시에 실행하는 것이 가능하여 Multi-programming의 사용도를 높일 수 있다.
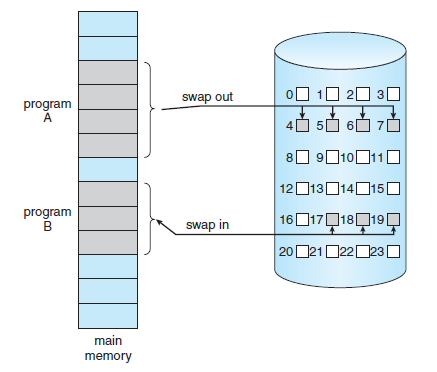
* 기본 스와핑(Standard Swapping)
- 기본 스와핑(Standard Swapping)은 Main Memory와 backing store 사이에서 프로세스를 이동시킨다. - backing store는 일반적으로 fast disk를 사용한다. - 이 저장 장치의 크기는 모든 사용자의 memory image를 저장할 만큼 커야 하며, 직접 접근이 가능해야 한다.
- 시스템은 실행할 준비가 된 모든 프로세스를 모아 ready queue에 가지고 있어야 하며, CPU 스케줄러는 다음 프로세스를 고를 때 dispatcher를 호출한다.
- dispatcher는 이 queue에 있는 다음 프로세스가 memory에 올라와 있는지를 확인하여, 만약 안 올라와 있다면 디스크에서 불러들어야 한다.
- 이 프로세스를 위한 공간이 memory에 없다면, 공간을 만들기 위해 현재 memory에 올라와 있는 프로세스를 내보낸다.(Swap out)
- 만약 사용자 프로세스의 크기가 100MB이고, backing store는 50MB/s의 전송률을 가진 디스크라고 하면, backing store로부터 100MB 프로세스를 전송하는 데 걸리는 시간은 100MB/(50MB/s) = 2s이다.
- Swap in과 Swap out을 해야 하므로 총 걸리는 시간은 2s X 2 = 4s이다.
- 한 프로세스가 스왑(swap)하기를 원한다면, 그 프로세스가 완전히 idle 하다는 것을 보장해야 한다. - 해당 프로세스가 I/O 장치의 어떤 신호를 주고받는 동안이라면, 그동안은 스왑(Swap)해서는 안 된다.
- 현대 운영체제들은 보통 기본 스와핑(Standard Swapping)을 사용하지 않는다. - 스와핑 시간이 오래 걸리므로, 실행에 할당되는 시간이 적어지기 때문이다. - 이에, 변형하여 swapping을 사용하는데 free memory가 threashold보다 부족하게 될 때만 swapping을 수행한다. - 또 다른 변형 Swapping은 프로세스 전체를 Swapping 하지 않고, 일부만을 Swapping 하여 사용한다.
* 모바일 시스템에서의 스와핑
- 보통 모바일 시스템은 어떠한 형태의 스와핑(Swapping)도 제공하지 않는 것이 일반적이다. - 대신, free memory가 정해진 Threshold보다 떨어지면 Apple의 iOS는 Application에게 할당된 memory를 자발적으로 반환하도록 요청한다. - Android는 Swapping을 지원하지 않고, free memory가 부족하다면 프로세스를 종료시키는 것이 가능하다.
8.3 연속 메모리 할당(Contiguous Memory Allocation)
- (Main) Memory는 일반적으로 두 개의 부분으로 나뉘는데, 하나는 Memory에 존재하는 운영체제를 위한 것이며, 다른 하나는 User Process를 위한 것이다.
* 메모리 보호(Memory Protection)
- 만일 시스템이 limit register와 relocation register를 가지고 있다면, 프로세스가 자신이 소유하지 않은 memory를 접근할 수 없게 강제할 수 있다.
- CPU 스케줄러가 다음으로 수행할 프로세스를 선택할 때, 디스패처(dispatcher)는 context switch의 부분으로 relocation register와 limit register에 정확한 값을 load 한다.
* 메모리 할당(Memory Allocation)
- 가장 간단한 memory allocation 방법은 memory를 똑같이 고정된 크기로 분할(partition) 하는 것이다. - 각 분할(Partition)마다 한 프로세스를 가지고, 이때 분할의 개수를 Multi-programming degree라고 부른다.
- 가변 분할(Variable-partition) 기법에서 운영체제는 memory의 어떤 부분이 사용되고 있고, 어떤 부분이 사용 되지 않고 있는가를 파악할 수 있는 테이블을 유지한다. - 초기에 모든 memory 공간은 한 개의 큰 사용 가능한 블록으로 구성되어 있으며, 이때 1개의 hole이 있다고 한다.
- 일반적으로 memory에는 다양한 크기의 free space가 여기저기 존재하게 된다. - 이런 memory에서는 동적 메모리 할당 문제(Dynamic Storage Allocation problem)이 있을 수 있다. - 이 문제는 free hole의 list로부터 size n의 block을 요구하는 것을 어떻게 만족시킬 것인가에 대한 문제이다. - 이 문제의 해결책은 대표적으로 아래 3가지가 있다.
(1) 최초 적합(first-fit) : 첫 번째 사용 가능한 가용 공간에 할당한다.
(2) 최적 적합(best-fit) : 사용 가능한 공간들 중에서 가장 작은 공간에 할당한다.
(3) 최악 적합(worst-fit) : 사용 가능한 공간들 중에서 가장 큰 공간에 할당한다.
* 단편화(Fragmentation)
- 앞에서 기술한 방법들은 외부 단편화(External fragmentation)가 발생한다. - 프로세스들이 memory에 load 되고, 제거되는 일이 반복되다 보면, 일부 free space는 사용하지 못할 만큼 작아진다.
- 최초 적합(first-fit)의 경우, 통계적인 분석을 통해 N 개의 block이 할당되었을 때 0.5N 개의 block이 단편화(Fragmentation) 때문에 손실될 수 있다고 알려져 있으며, 이를 50% 규칙이라고 한다.
- 18,464B의 free space에서 어느 한 프로세스가 18,462B를 요구하면, 2B의 hole이 남게 된다. - 이 경우, 2B의 hole을 위해 시스템이 더 큰 부담을 가진다. - 이에 일반적으로 memory를 작은 공간들로 분할한 뒤에, 이 공간 크기의 정수 배로 만 공간을 할당하는 것이 일반적이다.
- 이 경우 할당된 공간은 요구된 공간보다 약간 더 클 수 있는데, 이 두 공간의 크기 차이를 내부 단편화(Internal fragmentation)이라고 한다.
- 외부 단편화 문제를 해결하는 방법으로는 압축(Compaction)이 있다. - 이 방법은 memory의 모든 내용을 한 군데로 몰고, 모든 free space들을 다른 한 군데로 몰아서 큰 block을 만드는 방법이다.
8.4 세그먼테이션(Segmentation)
- 세그먼테이션은 프로그래머가 인지하는 memory의 모습을 실제 physical memory의 모습으로 변환해주는 기법을 제공한다.
* 기본 방법(Basic Method)
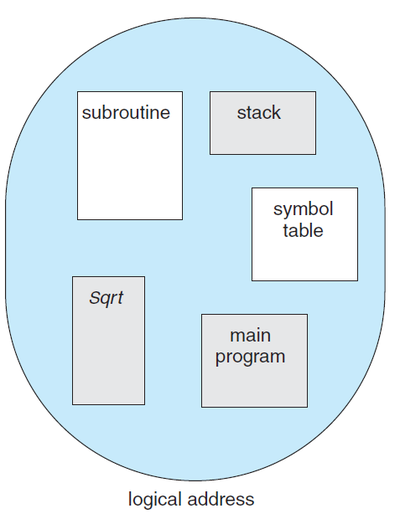
- 프로그래머가 생각하는 프로그램의 모습은 아래 그림과 같이 가변적인 길이를 가지는 모습이다.
Programmer's view of a program.
- 세그먼테이션(Segmentation)은 위와 같이 프로그래머가 생각하는 모양을 그대로 지원하는 메모리 관리 기법. - 프로그래머가 생각하는 논리 구조 공간(Logical address space)은 세그먼트들의 집합으로 이루어진다.
* 하드웨어(Hardware)
- Segment table의 각 항목은 Segment의 base와 limit를 가지고 있다. - Segment base는 Segment의 시작 주소를 나타내며, Segment limit은 Segment의 길이를 명시한다. - 세그먼테이션(Segmentation)의 예시는 아래와 같다.
example of segmentation
8.5 페이징(Paging)
- 세그먼테이션(Segmenation)은 프로세스가 load 되는 물리 주소 공간이 연속적이지 않더라도 load를 허용한다. - 페이징(Paging)은 위의 이점을 가지면서, 단편화에 따른 압축 작업이 필요 없다. - 또한, 페이징(Paging)은 swap-out 되는 다양한 크기의 세그먼트를 backing storage에 저장해야 하는 문제도 해결한다.
* 기본 방법(Basic Method)
- 물리 메모리(Physical Memory)는 프레임(Frame)이라 불리는 같은 크기의 block으로 나누어진다. - 논리 메모리(Logcial Memory)는 페이지(Page)라 불리는 같은 크기의 block으로 나누어진다.
- 프로세스가 실행될 때, 그것의 페이지는 파일 시스템이나 예비 저장 장치로부터 가용한 main memory frame으로 load 된다.
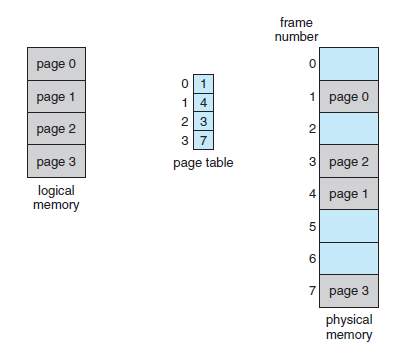
- CPU에서 나오는 모든 주소는 페이지 번호(p)와 페이지 변위(d) 두 개의 부분으로 이루어진다. - 페이지 번호(p)는 페이지 테이블(Page Table)을 access 할 때 사용되며, 페이지 테이블은 main memory에서 각 page가 점유하는 주소를 가지고 있다.
Paging model of logical and physical memory
- 아래 그림에서 논리 주소 0은 페이지(page) 0, 변위(offset) 0이다. - 페이지 테이블을 색인으로 찾아서 페이지(page) 0이 프레임(frame) 5에 있다는 것을 알아낸다. - 이에 논리 주소 0은 실제 주소 20 ( = (5 X 4) + 0)에 mapping 된다.
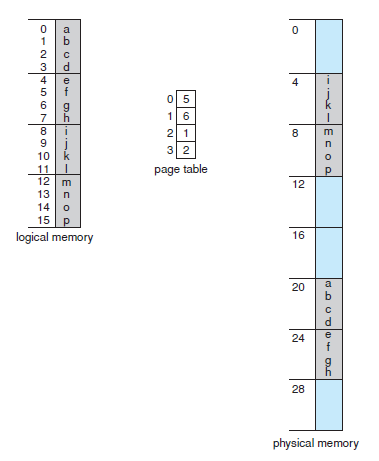
Paging example for a 32-byte memory with 4-byte pages
- 페이징(Paging) 그 자체는 동적 재배치의 한 형태이다. - 페이징 기법을 사용하면 외부 단편화는 발생하지 않지만, 내부 단편화는 발생될 수 있다. - 예를 들어, 페이지 크기가 2048 Byte이고, 프로세스가 72,766 Byte를 요구한다면, 35개의 Page Frame을 할당하고, 1086Byte가 남게 된다.
- 이때, 36개의 Page Frame을 할당하면 36번째 Page Frame은 2048-1086 = 962Byte의 내부 단편화가 발생한다.
- 이에 작은 페이지 크기가 바람직할 수 있지만, 너무 작게 되면 페이지 테이블의 크기가 커지게 될 수 있다.
- 한 프로세스가 실행되기 위해 도착하면, 그 프로세스의 크기가 페이지 몇 개 분에 해당하는가를 조사한다. - 각 사용자 페이지(Page)는 한 프레임(Frame) 씩을 필요로 한다.
- 페이징의 가장 중요한 특징은 memory에 대한 프로그래머의 인식과 실제 내용이 서로 다를 수 있다는 점이다. - 프로그래머는 memory가 하나의 연속적인 공간으로 이루어졌다고 생각할 수 있다. - 그러나, 실제로는 프로그램은 여러 곳에 프레임 단위로 분산되어 있고, 많은 다른 프로그램들이 존재하고 있다.
- 운영체제는 memory를 관리하기 때문에, 물리 Memory에 Allocation Details에 대해 파악하고 있어야 한다. - 어느 프레임이 사용 가능 한지, 총 프레임이 몇 개인지에 대한 정보가 프레임 테이블(Frame Table)에 존재한다. - 운영체제는 모든 프로세스들의 주소들을 실제 주소로 mapping 할 수 있어야 한다.
* 하드웨어 지원(Hardware Support)
- 각 운영체제는 페이지 테이블을 저장하기 위한 고유의 방법을 가지고 있다. - 몇몇 OS는 각 프로세스마다 하나의 page table을 할당한다.
- 페이지 테이블이 작은 경우에 register들의 집합으로 구현될 수 있다. - 페이지 테이블의 크기가 큰 경우에는 페이지 테이블을 주 메모리(Main Memory)에 저장하고, 페이지 테이블 기준 레지스터(PTBR)로 하여금 페이지 테이블을 가리키도록 한다.
- 이 방식은 context switch 시간을 줄일 수 있지만, 메모리 접근 시간을 늘릴 수 있다. - 이에 TLB(Translation Look-aside Buffers)로 불리는 특수한 소형 hardware cache가 사용된다.
- 접근하려는 memory의 page 번호가 TLB에서 발견되는 비율을 적중률(hit ratio)라고 한다. - 예를 들어, 80%의 적중률이란 TLB에서 원하는 page 번호를 발견할 횟수가 80%라는 것을 의미한다.
- Main memory를 접근하는데 총 100ns가 소요된다면, 원하는 데이터를 접근하는 데 총 100ns가 걸린다. - 만약 TLB에서 페이지 번호를 찾지 못하면, 페이지 테이블에 접근(100 ns), 원하는 데이터를 메모리에서 읽어야(100ns) 하므로 (100ns + 100ns = 200ns)의 시간이 소요된다.
- 만약 hit ratio가 80% 라면 실제 접근 시간은 0.80 X 100 + 0.20 X 200 = 120 ns가 된다. - 만약 hit ratio가 99% 라면, 실제 접근 시간은 0.99 X 100 + 0.01 X 200 = 101 ns가 된다.
* 보호(Protection)
- 페이지화된 환경에서 memory 보호는 각 페이지에 붙어 있는 protection bits에 의해 구현된다. - 각 비트는 이 페이지가 읽기 전용인지 쓰기가 가능한지를 정의할 수 있다.
- 페이지 테이블의 각 엔트리에는 유효/무효(valid/invalid)라는 하나의 비트가 더 있다. - 이 비트가 유효로 설정되면, 관련된 페이지가 프로세스의 합법적인 페이지임을 나타낸다. - 이 비트가 무효로 설정되면, 그 페이지는 프로세스의 논리 주소 공간에 속하지 않는다는 것을 나타낸다.
- 몇몇 시스템은 페이지 테이블의 크기를 나타내기 위해 페이지 테이블 길이 레지스터(PTLR)을 제공한다. - 프로세스가 제시한 주소가 유효한 범위 내에 있는지를 확인하기 위해 모든 논리 주소 값이 PTLR과 비교된다.
* 공유 페이지(Shared Pages)
- 페이징(Paging)의 또 다른 장점은 코드를 쉽게 공유할 수 있다는 점이다. (Multi-tasking에서 중요) - 재진입 가능 코드는 수행하는 동안 절대 변하지 않고, 두 개나 그 이상의 processor들이 동시에 같은 코드를 수행할 수 있다.
8.6 페이지 테이블의 구조(Structure of Page Table)
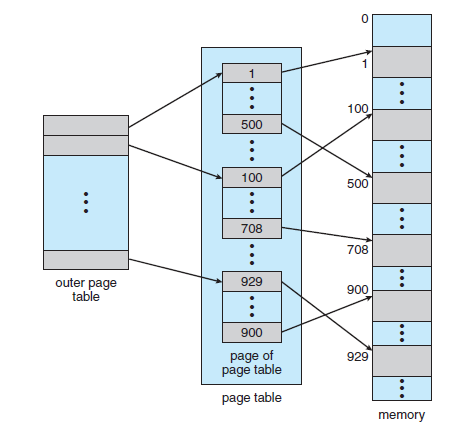
* 계층적 페이징(Hierarchical Paging)
- 많은 컴퓨터들이 매우 큰 주소 공간을 가지므로, 페이지 테이블의 크기도 맞춰서 커지고 있다.
- 만약 32bit 논리 주소 공간을 가진 시스템에서 페이지의 크기가 4KB라면, 페이지 테이블은 (2^32 /2^12)로 대략 100만 개의 항목으로 구성될 것이다.
- 이에 커지는 페이지 테이블을 Main memory에 연속적으로 할당하기 보다, 페이지 테이블을 여러 개로 나누어 사용하는 방법이 가능하다.
- 대표적인 방법 중 하나는 2단계 페이징 기법(Two-level paging scheme)로 페이지 테이블 자체를 다시 페이지화하는 것이다.
Two-level page-table scheme
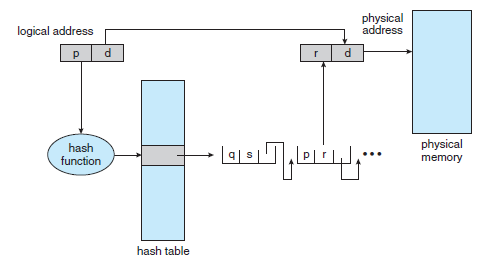
* 해시 페이지 테이블(Hash Page Tables)
- 주소 공간이 32비트보다 커지면, 가상 주소를 hash로 사용하는 hash page table을 많이 쓴다.
- 해시 페이지 테이블(Hash Page Table) 알고리즘은 다음과 같이 작동한다.
(1) 가상 주소 공간으로부터 페이지 번호가 오면 그것을 hashing 한다. (2) 그 값으로부터 hash page table에서 연결 리스트를 따라가며 첫 번째 원소와 가상 페이지 번호를 비교한다. (3) 일치되면, 그에 대응하는 페이지 프레임 번호를 가져와 물리 주소를 얻는다.
Hash Page Table
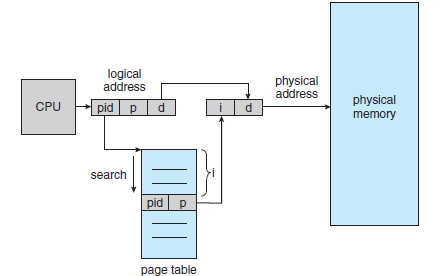
* 역 페이지 테이블(Inverted Page Table)
- 운영체제는 프로세스가 가상 페이지 주소를 제시할 때마다 이 테이블에 와서 그것을 실제 페이지 주소로 변환해 주어야 한다. - 이때 테이블이 오름차순으로 정렬되어 있기 때문에, 페이지 테이블이 클 경우 많은 메모리 공간을 점유한다.
- 이 문제를 해결하는 방법 중 하나는 역 페이지 테이블(Inverted Page Table)을 사용하는 것이다. - 역 페이지 테이블(Inverted Page Table)에서는 메모리 frame마다 한 항목씩을 할당한다. - 각 항목은 그 frame에 올라와 있는 페이지 주소, 페이지를 소유하고 있는 프로세스의 ID를 표시한다.
Inverted Page Table
- 역 페이지 테이블을 사용하는 시스템에서 Memory의 공유는 더 어렵다. - Memory의 공유는 보통 하나의 physical memory에 mapping 되는 여러 개의 가상 주소를 통해 구현된다. - 이 방법은 모든 physical page에 대해 하나의 가상 주소를 갖게 하는 이 구조에서는 사용할 수 없다.
-Reference- Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 9th』
CHAPTER 7 - 교착상태(Deadlocks) CH 7에서는, - 첫째로, 교착상태(Deadlock)에 대해서 알 수 있다. - 둘째로, 교착상태(Deadlock)을 예방하거나 회피하는 방법에 대해서 알 수 있다.
- 대기 중인 프로세스들이 다시는 그 상태를 변경시킬 수 없는 상황을 교착상태(Deadlock)이라고 한다.
7.1 시스템 모델(System Model)
- 시스템은 경쟁하는 프로세스들 사이에 분배되어야 할 유한한 수의 resource로 구성된다.
- 정상적인 작동 모드이면, 프로세스는 다음 순서로만 resource를 사용할 수 있다. 1. 요청(Request) : 프로세스가 resource을 요청한다. 만약 얻지 못하면, resource을 얻을 때까지 대기해야 한다. 2. 사용(Use) : 프로세스가 resource에 대해 작업을 수행할 수 있다. 3. 방출(Release) : 프로세스가 resource를 방출한다.
- 한 프로세스 집합 내의 모든 프로세스가 집합 내의 다른 프로세스에 의해서만 발생될 수 있는 사건을 기다린다면, 그 프로세스 집합은 교착상태(Deadlock)에 있다.
7.2 교착상태의 특징(Deadlock Charcterization)
- 교착상태(Deadlock)에 있는 프로세스들은 실행을 끝낼 수 없으며, 시스템 자원이 묶여 있어서 다른 작업을 시작하는 것도 불가능하다.
* 필요조건들(Necessary Conditions)
- 교착상태(Deadlock)은 한 시스템에 다음 네 가지 조건이 동시에 성립될 때 발생할 수 있다.
1. 상호 배제(Mutual Exclusion) : 최소한 하나의 resource는 nonsharable mode로 점유되어야 한다. nonsharable mode에서는 한 번에 하나의 프로세스만이 해당 resource를 사용할 수 있다.
2. 점유하며 대기(Hold-and-wait) : 프로세스는 최소한 하나의 resource를 점유한 채, 현재 다른 프로세스에 의해 점유된 resource를 추가로 얻기 위해 반드시 대기해야 한다.
3. 비선점(No preemption) : resource들을 선점할 수 없어야 한다. 즉, resource가 강제적으로 방출될 수 없고, 점유하고 있는 프로세스가 task를 종료한 후, 그 프로세스에 의해서만 resource가 자발적으로 방출될 수 있다.
4. 순환 대기(Circular wait) : 대기하고 있는 프로세스의 집합 {P(0), P(1), ... , P(n)}에서 P(0)는 P(1)이 점유한 resource를 대기하고, P(1)은 P(2)가 점유한 resource을 대기하고, .... , P(n)은 P(0) 가진 resource을 대기한다.
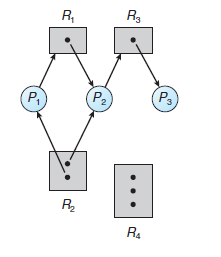
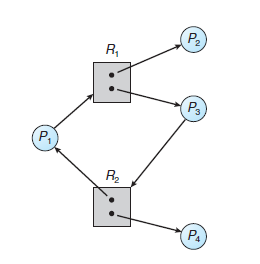
* 자원 할당 그래프(Resource-Allocation Graph)
- deadlock은 시스템 자원 할당 그래프(system resource-allocation graph)로 보다 정확하게 기술될 수 있다. - P(i) → R(j)는 요청 간선(Request Edge)이고, R(j) → P(i)는 할당 간선(Assignment Edge)이다.
- 자원 할당 그래프에서 사이클(Cycle)을 포함하지 않으면, 시스템 내에 어느 프로세스도 교착상태(Deadlock)이 아니라는 것을 보일 수 있다.
- 하지만, 만일 각 resource type이 여러 개의 instance를 가지면, cycle이 반드시 교착상태(Deadlock)이 발생했음을 의미하지는 않는다.
- 요약하자면, 자원 할당 그래프에서 사이클이 없다면 시스템은 교착상태(Deadlock)이 100% 아니다. - 반면에, 사이클이 있다면 시스템은 교착상태에 있을 확률이 있는 상태이다.
7.3 교착상태 처리 방법(Methods for Handling Deadlocks)
- 원칙적으로 교착상태(Deadlock) 문제를 처리하는데 다음과 같은 세 가지 방법이 있다.
(1) 교착상태(Deadlock)을 예방하거나 회피하는 protocol을 사용한다. - 교착상태(Deadlock) 예방은 앞서 언급한 4가지 조건 중 적어도 하나가 성립하지 않도록 하는 방법이다. - 교착상태(Deadlock) 회피는 프로세스가 일생 동안 요구하고 사용할 resource에 대한 부가적인 정보를 얻은 뒤 그 정보를 바탕으로 프로세스를 기다려야 할지 결정할 수 있다.
(2) 시스템이 교착상태(Deadlock)가 가능하도록 허용한 다음에 회복시키는 방법이 있다. - 교착상태(Deadlock) 예방이나 회피를 사용하지 않으면, 교착상태가 발생할 수 있다. 이에 교착상태가 진짜로 발생했는지에 대한 여부를 조사하는 알고리즘과 교착상태 복구 알고리즘을 사용할 수 있다.
(3) 문제를 무시하고, 교착상태(Deadlock)이 시스템에서 절대 발생하지 않는 척한다. - 오히려 발생한 교착상태를 해결하는 데 더 비용이 많이 들 수 있으므로, 무시해버릴 수도 있다. - 이 경우, 계속된 교착상태로 시스템 성능을 저하시킬 가능성도 있기 때문에, 수작업으로 다시 시작할 필요가 있다.
7.4 교착상태 예방(Deadlock Prevention)
- 앞서 언급한 4가지 교착상태 발생 조건들 중에 적어도 하나가 성립하지 않도록 하여 교착상태를 예방할 수 있다.
* 상호 배제(Mutual Exclusion)
- 상호 배제는 적어도 하나의 resource는 공유 불가능한 resource 여야 한다는 조건이다. 이에 공유 가능한 resource에 대해서는 교착상태(Deadlock)이 일어나지 않는다. (ex) 읽기-전용 파일
* 점유하며 대기(Hold and Wait)
- 프로세스가 resource를 요청할 때, 다른 resource들을 점유하지 않을 것을 보장하면 교착상태 예방이 가능하다.
- 첫 번째 방법은 프로세스가 전혀 resource를 갖고 있지 않을 때만, resource을 요청하도록 허용하면 된다.
- 위 방법에서 다른 추가 resource를 요청하려면, 현재 자신에게 할당된 resource를 모두 방출해야 한다.
- 두 번째 방법은 프로세스가 초기에는 DVD drive와 Disk file만 요청하도록 허용하는 방법이다.
- 이 두 protocol에는 2가지 단점이 있다.
(1) 많은 resource들이 할당된 후 오랫동안 사용되지 않기 때문에, resource의 이용도가 낮을 수 있다.
(2) 기아(Starvation) 문제가 발생할 수 있다. (특정 프로세스는 무한정 대기하는 상황이 나올 수 있다.)
* 비선점(No Preemption)
- 교착상태(Deadlock)을 보장하는 세 번째 조건은 할당된 resource이 선점되지 않아야 한다는 점이다.
- 이 조건을 성립하지 않게 하기 위해, 어떤 resource을 점유하고 있는 프로세스가 즉시 할당할 수 없는
다른 resource을 요청하면, 현재 점유하고 있는 모든 resource들이 선점되게 할 수 있다.
* 순환 대기(Circular Wait)
- 교착상태(Deadlock)을 보장하는 네 번째 조건은 순환 대기(Circular wait) 조건이다.
- 이 조건을 성립하지 않게 하기 위해, 모든 resource type에 대해 전체적인 순서를 부여하여,
각 프로세스가 열거된 순서대로, 오름차순으로 resource을 요청하도록 요구하게 할 수 있다.
7.5 교착상태 회피(Deadlock Avoidance)
- 교착상태 예방 방법을 쓰면, 장치의 이용률이 저하되고 시스템 처리율(Throughput)이 감소될 수 있다.
- 교착상태 회피는 resource가 어떻게 될지 추가 정보를 통해서 이루어진다.
* 안전 상태(Safe State)
- 시스템 상태가 안전(Safe) 하다는 말은 시스템이 어떤 순서로든 프로세스들이 요청하는 resource를 교착상태(Deadlock)을 발생시키지 않고, 차례로 모두 할당해 줄 수 있다는 것을 의미한다.
- 시스템이 안전 순서(Safe Sequnece)를 찾을 수 있다면 시스템은 안전(safe) 하다고 말할 수 있다. - 시스템이 안전하다는 것은 교착상태(Deadlock)가 발생하지 않는다는 것을 의미한다.
- 시스템이 안전 순서(Safe Sequence)를 찾을 수 없다면 시스템은 불안전(unsafe) 한 상태에 있다. - 시스템이 불안전하다는 것은 반드시 교착상태(Deadlock)으로 간다는 것을 의미하지 않는다. - 대신, 시스템이 불안전하다는 말은 "앞으로 교착상태로 갈 확률이 있다."라는 뜻을 의미한다.
- 예를 들어, 시스템에는 12개의 tape가 있고 세 개의 프로세스 상황은 아래와 같을 때,
최대 소요량
현재 사용량
P(0)
10
5
P(1)
4
2
P(2)
9
2
(1) 먼저 tape 3개(12 - (5+2+2)) 중 2개를 P(1)에 할당하여 P(1)을 완료시킨 뒤, tape 4개를 돌려받는다. (2) 이제 여분의 5개의 tape를 P(0)에 모두 할당하여, P(0)를 완료시키고 tape 10개를 돌려받는다. (3) P(2)를 완료시킨다.
- 이에 안전 순서(Safe Sequence) <P(1), P(0), P(2)>가 있으므로, 위 시스템은 안전(safe) 하다고 할 수 있다. - 하지만, 위의 시스템에서 P(2)의 현재 사용량이 3이었다면 시스템은 불안전(unsafe) 한 상태로 변경된다.
- 시스템을 항상 안전(Safe) 한 상태로 유지하게 하여 교착상태(Deadlock)을 회피할 수 있다. - 하지만, 이 방법은 프로세스가 요청한 resource보다 시스템이 더 많은 resource을 갖고 있더라도 때에 따라 그 프로세스를 기다리게 할 수 있으므로, resource의 utilization이 더 낮아질 수 있다.
* 자원 할당 그래프 알고리즘(Resource-Allocation Graph Algorithm)
- 자원 할당 그래프를 그려보면서 cycle이 안 생기게 하여 교착상태(Deadlock)을 회피할 수 있다. - 요청 간선, 할당 간선과 함께 점선으로 예약 간선을 사용할 수 있다. - 그래프에서 cycle이 없다면, resource를 할당해도 시스템은 안전 상태가 된다. - cycle이 발생하게 되면, 시스템은 불안전한 상태가 되므로 교착상태를 회피할 수 없게 된다.
* 은행원 알고리즘(Banker's Algoirthm)
- 자원 할당 그래프 알고리즘은 종류마다 자원이 여러 개씩 있게 되면 사용할 수 없다. - 은행원 알고리즘(Banker's Algorithm)에서는 자원이 여러 개씩 있더라도 사용할 수 있다.
- 은행원 알고리즘에서는 아래와 같은 자료구조를 사용한다. (n : 프로세스의 수, m : resource의 수)
(1) Available : 각 종류 별로 available 한 resource의 개수를 나타내는 벡터이다. Available[j] = k 이면, 현재 R(j)를 k 개 사용할 수 있다는 뜻이다.
(2) Max : 각 프로세스가 최대로 필요로 하는 resource의 개수를 나타내는 행렬로, 크기가 n X m이다. Max[i][j] = k 이면, P(i)가 R(j)를 최대 k 개까지 요청할 수 있음을 나타낸다.
(3) Allocation : 각 프로세스에게 현재 나가있는 resource의 개수를 나타내는 행렬로, 크기가 n X m이다. Allocation[i][j] = k 이면, 현재 P(i)가 R(j)를 k 개 사용 중임을 나타낸다.
(4) Need : 각 프로세스가 이후 요청할 수 있는 resource의 개수를 나타내는 행렬로, 크기가 n X m이다. Need[i][j] = k라면, 이후 R(j)를 k 개까지 더 요청할 수 있음을 나타낸다.
- Need[i][j] = Max[i][j] - Allocation[i][j]의 관계가 있다.
- 안전성 알고리즘(Safety Algorithm) (1) Work와 Finish는 각각 크기가 m과 n인 vector이다. Work를 Available 값으로 초기화해주고, i = 0, 1, ... , n-1에 대하여 Finish[i] = false를 초깃값으로 준다.
(2) 다음 두 조건을 만족하는 i 값을 찾는다. (a . Finish[i] == false b. Need(i) <= Work)
(3) Work = Work + Allocation(i) Finish[i] = true로 한 뒤에 두 번째 단계로 간다.
(4) 모든 i 값에 대해 Finish[i] = true 이면, 이 시스템은 안전 상태에 있다.
- 자원 요청 알고리즘(Resource-Request Algorithm) (1) 만약 Request(i) <= Need(i)이면, 두 번째 단계로 가고, 아니면 오류로 처리한다.
(2) 만약 Request(i) <= Available 이면, 세 번째 단계로 가고, 아니면 프로세스는 기다려야 한다.
(3) 마치 시스템이 P(i)에게 resource를 할당해준 것처럼 시스템 상태 정보를 아래처럼 바꾼다.
Available = Available - Request;
Allocation_i = Allocation_i + Request;
Need_i = Need_i - Request;
- 예시 (Example)
Allocation, Max, Available 배열이 아래와 같을 때,
Allocation (A B C)
Max (A B C)
Available (A B C)
A B C
A B C
A B C
P(0)
0 1 0
7 5 3
3 3 2
P(1)
2 0 0
3 2 2
P(2)
3 0 2
9 0 2
P(3)
2 1 1
2 2 2
P(4)
0 0 2
4 3 3
Need 배열은 아래와 같다. (Max - Allocation = Need)
Need (A B C)
A B C
P(0)
7 4 3
P(1)
1 2 2
P(2)
6 0 0
P(3)
0 1 1
P(4)
4 3 1
- 위의 시스템은 안전하다(Safe)라고 할 수 있는데, <P(1), P(3), P(4), P(2), P(0)>의 sequence가 있기 때문이다.
7.6 교착상태 탐지(Deadlock Detection)
- 만약 시스템이 교착상태(Deadlock) 예방이나 회피 알고리즘을 사용하지 않는다면, 교착상태가 발생할 수 있다. - 이러한 환경에서는 시스템이 아래 알고리즘들을 반드시 지원해야 한다. (1) 교착상태(Deadlock)이 발생했는지 결정하기 위해 시스템의 상태를 검사하는 알고리즘 (2) 교착상태(Deadlock)으로부터 회복하는 알고리즘
* 각 자원 타입이 한 개씩 있는 경우(Single Instance of Each Resource Type)
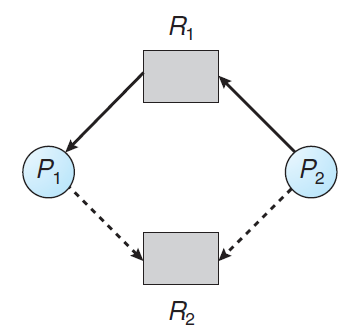
- 모든 자원들이 한 개의 instance만 있다면, 대기 그래프(wait-for graph)를 이용하여 교착상태(Deadlock) 탐지 알고리즘을 정의할 수 있다.
(a) 자원 할당 그래프 (b) a에 대응되는 대기 그래프
- 교착상태(Deadlock)을 탐지하기 위해 시스템은 대기 그래프를 유지할 필요가 있고, 주기적으로 그래프에서 cycle을 탐지하는 알고리즘을 호출한다.
* 각 타입의 자원을 여러 개 가진 경우(Several Instances of a Resource Type)
- 대기 그래프(Wait-for graph)는 각 종류마다 resource가 여러 개씩 존재하는 상황에서는 사용할 수 없다.
- 따라서, 은행원 알고리즘과 유사하게 자료구조를 사용해야 한다.
* 탐지 알고리즘 사용(Detection-Algorithm Usage)
- 탐지 알고리즘(Detection-Algorithm)은 언제 돌려야 하는지에 대해서는 두 가지를 살펴봐야 한다. (1) 교착상태(Deadlock)가 얼마나 자주 일어나는가? (2) 교착상태(Deadlock)이 일어나면, 통상 몇 개의 프로세스가 거기에 연루되는가?
- 교착 상태가 자주 일어난다면, 탐지 알고리즘(Detection Algorithm)도 자주 돌려아 한다.
- 교착상태(Deadlock)이 일어나는 시점은 "어떤 프로세스가 resource를 요청했는데, 그것이 즉시 만족되지 못하는 시점"이다.
7.7 교착상태 회복(Deadlock Recovery)
- 탐지 알고리즘을 통해 교착상태(Deadlock)이 존재한다고 결정되면, 운영자가 수작업으로 처리하는 것이 한 가지 방법이 될 수 있다.
- 또 다른 방법은, 자동적으로 교착상태(Deadlock)로부터 회복(Recovery) 하게 하는 것이다.
- 자동적인 회복을 위해 프로세스를 종료시키는 것과 자원을 선점하는 것 두 가지 종류가 있을 수 있다.
* 프로세스 종료(Process Termination)
- 종료된 프로세스로부터 할당되었던 모든 자원을 회수하게 한다.
(1) 교착상태(Deadlock) 프로세스를 모두 중지 : 이 방법은 확실하게 교착상태(Deadlock)의 cycle을 깨트리지만, 관련된 모든 프로세스를 중지시키므로 비용이 커진다.
(2) 교착상태(Deadlock)가 제거될 때까지 한 프로세스 씩 중지 : 각 프로세스가 중지될 때마다, 탐지 알고리즘을 통해 교착상태(Deadlock)이 존재하는지를 확인해야 하므로, 상당한 overhead를 유발할 수 있다.
- 어떤 프로세스를 먼저 중지시켜야 하는가는 아래와 같은 기준들이 있을 수 있다. (1) 프로세스의 우선순위가 어떠한지 (2) 지금까지 프로세스가 수행된 시간과 종료하는 데까지 더 필요한 시간 (3) 프로세스가 종료하기 위해 필요한 추가 resource의 수 (4) 프로세스가 사용한 resource type과 수
* 자원 선점(Resource Preemption)
- 자원 선점(Resource Preemption)을 이용하여 교착상태(Deadlock)을 제거하려면, 교착상태가 깨어질 때까지 프로세스로부터 Resource을 계속적으로 선점해 이들을 다른 프로세스에게 주어야 한다.
- 교착상태(Deadlock)을 해결하기 위해 선점이 필요하다면, 다음의 세 가지 사항을 고려해야 한다. (1) 희생자 선택(Selection of a victim) : 어느 resource와 process가 선점될 것인가? (2) 후퇴(Rollback) : 프로세스로부터 자원을 선점하려면, 그 프로세스를 어떻게 해야 하는가? (3) 기아 상태(Starvation) : 기아(Starvation) 상태가 발생하지 않는다는 것을 어떻게 보장해야 하는가?
-Reference- Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 9th』