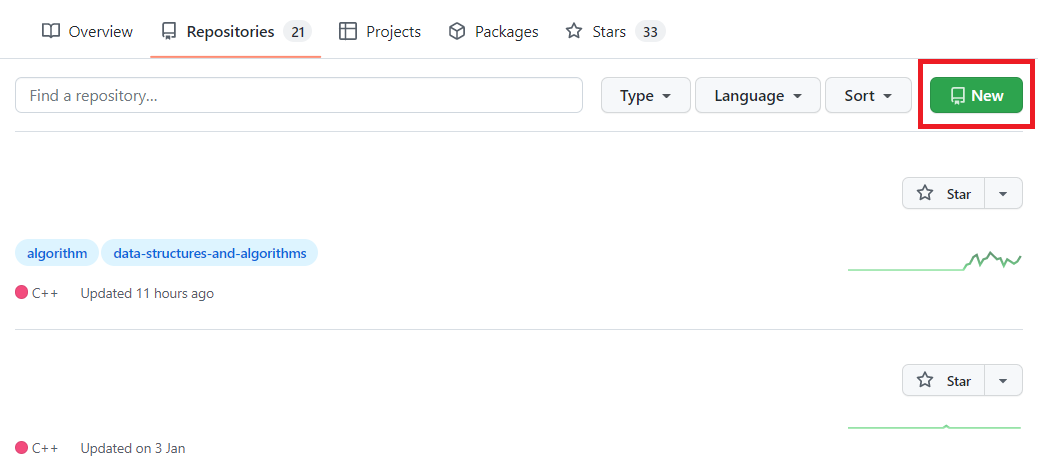
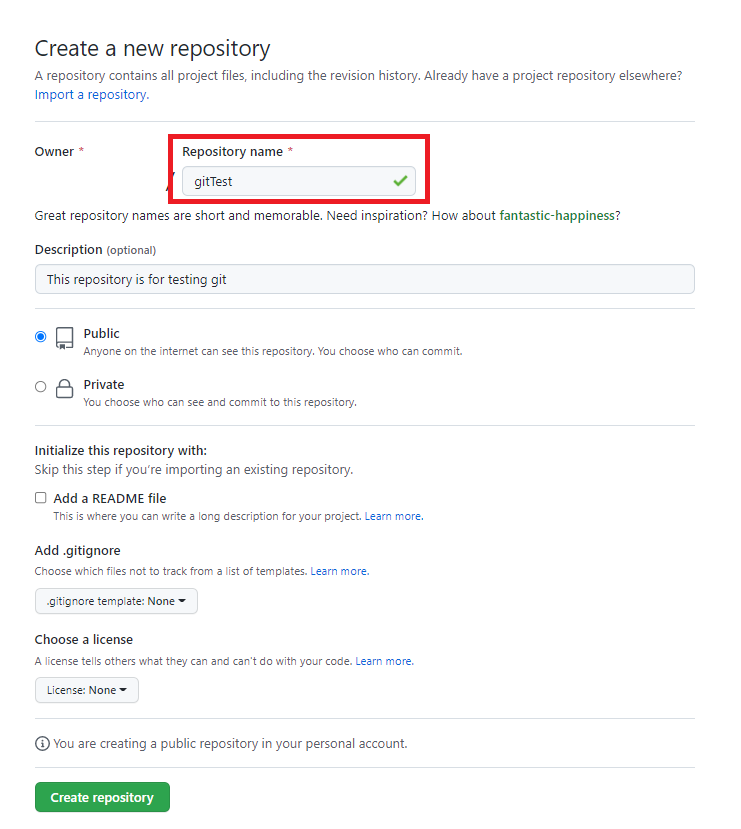
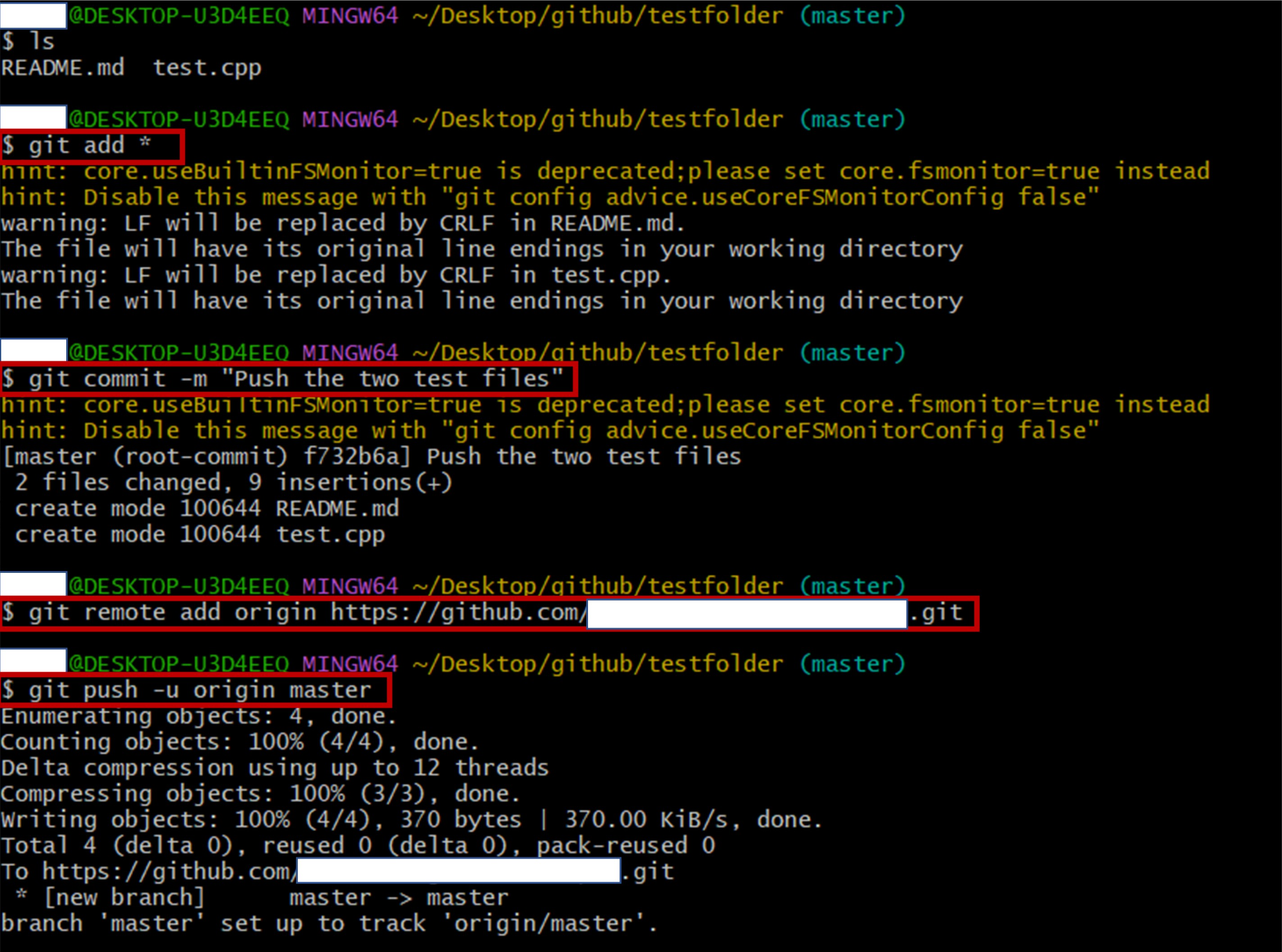
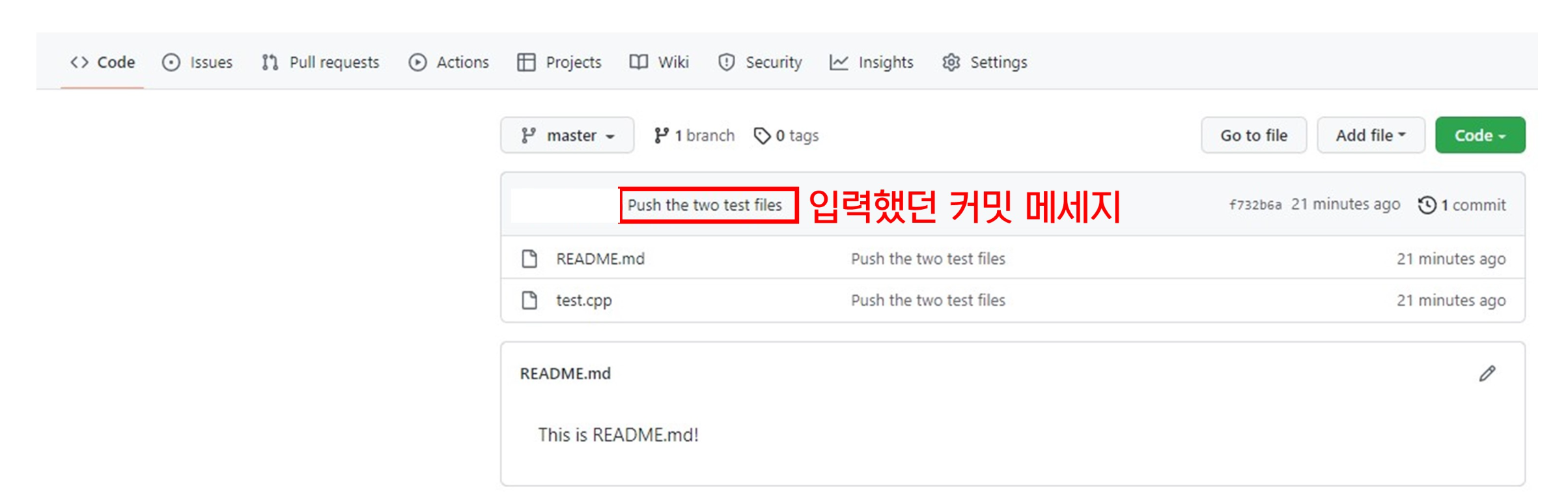
- 필요한 데이터만 선택적으로 출력하게 하는 WHERE절 - WHERE절은 SELECT문으로 데이터를 조회할 때, 특정 조건을 기준으로 원하는 행만 출력할 수 있음.
SELECT [조회할 열1], [조회할 열1], … , [조회할 열N]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하기 위한 조건식];
- 여러 개의 조건식을 사용할 수 있게 하는 AND, OR 연산자 - 논리 연산자(AND, OR)는 WHERE 절에서 조건식을 여러 개 지정할 수 있도록 해줌.
SELECT [조회할 열1], [조회할 열1], … , [조회할 열N]
FROM [조회할 테이블 이름]
WHERE [조건식 1]
AND [조건식 2]
AND [조건식 3]
OR [조건식 4];
- 연산자 종류와 활용방법 1. 산술 연산자 (+, - , *, /): 사칙 연산을 가능하게 해줌. 2. 비교 연산자: 대소 비교 연산자(>, >=, <, <=)와 등가 비교 연산자(=, !=, <>, ^=)가 있음. 3. 논리 부정 연산자(NOT): 특정 판단값을 반대로 변경함. (True->False, False->True) 4. IN 연산자: OR을 여러번 사용해야 할 때, 대신 사용될 수 있음. 5. BETWEEN A AND B 연산자: 최솟값과 최댓값을 통해 범위를 설정할 때 사용됨. (ex) 보유잔액이 2000원이상 3000원 미만
6. LIKE 연산자와 와일드카드: - LIKE 연산자는 게시판 제목 검색 기능처럼 일부 문자열이 포함된 데이터를 조회할 때 사용함. - 와일드카드란 특정문자 또는 문자열을 대체하거나 문자열 데이터의 패턴을 표기하는 특수문자로, 2가지 종류가 있음. (1) -: 어떤 값이든 상관없이 한 개의 문자 데이터를 의미 (2)%: 길이와 상관없이 (문자 없는 경우도 포함) 모든 문자 데이터를 의미
7. IS NULL 연산자: 특정 열 또는 연산 결과 값이 NULL 인지 여부를 확인함.
8. 집합 연산자: 두 개 이상의 SELECT문의 결과 값을 연결할 때 사용함. (ex) 10번 부서의 사원과 20번 부서의 사원을 합칠 때 - 출력 열 개수와 각각 대응되는 열의 자료형을 맞춰주어야 함. - 집합 연산자는 4개가 있음. (1)UNION: 연결된 SELECT 문의 결과 값을 합집합으로 묶어줌. (중복값 제거) (2)UNION ALL: 연결된 SELECT 문의 결과 값을 합집합으로 묶어줌. (중복값 유지) (3)MINUS: 먼저 작성된 SELECT 문의 결과값에서 다음 SELECT 문의 결과 값을 차집합처리 (4)INTERSECT: 먼저 작성한 SELECT문과 다음 SELECT문의 결과 값이 같은 데이터만 출력
- 연산자 우선순위 (*,/) > (+,-) > (=, !=, ^=, <>, >, >=, <, <=) > (IS NULL, LIKE, IN) > (BETWEEN A AND B) > NOT > AND > OR
- 데이터를 조회하는 3가지 방식 1. 셀렉션(Selection): 행 단위로 원하는 데이터를 조회하는 방식 2. 프로젝션(Projection): 열 단위로 원하는 데이터를 조회하는 방식 3. 조인(Join): 두 개 이상의 테이블을 양 옆에 연결하여 하나의 테이블 인 것처럼 조회하는 방식
- SELECT절과 FROM절 - SELECT 문은 데이터에 보관되어 있는 데이터를 조회하는 데 사용 - FROM절은 조회할 데이터가 저장된 테이블 이름을 명시 - 아래 SQL문은 EMP 테이블의 전체열을 조회함.
SELECT *
FROM EMP;
- 중복 데이터를 삭제하는 DISTINCT - SELECT 문으로 데이터를 조회한 후 DISTINCT를 사용하여 중복을 제거할 수 있음. - DISTINCT를 사용하면, 명시한 열들 중에서 중복 행 한개만 남겨두고 모두 제거됨.
SELECT DISTINCT deptno,
FROM emp;
- 한눈에 보기 좋게 별칭(Alias) 설정하기 - ORACLE DB에서 별칭을 지정하는 4가지 방식 1. 연산 및 각오된 문장 이후 한 칸 띄우고 별칭 지정 (ex) sal*12+comm ANNSAL 2. 연산 및 각오된 문장 이후 한 칸 띄우고 별칭을 큰따옴표로 묶음 (ex) sal*12+comm "ANNSAL" 3. 연산 및 각오된 문장 이후 한 칸 띄운 후 ‘AS’, 한 칸 뒤에 별칭 지정 (ex) sal*12+comm AS ANNSAL 4. 연산 및 각오된 문장 이후 한 칸 띄운 후 ‘AS’, 한칸 뒤에 별칭을 큰 따옴표로 묶음 (ex) sal*12+comm AS "ANNSAL"
- 원하는 순서로 출력 데이터를 정렬하는 ORDER BY - 정렬 옵션의 default는 ASC(오름차순)이다. 정렬옵션에 DESC 사용 시에 내림차순으로 정렬가능하다. - 꼭 필요한 경우가 아니라면, 사용하지 않는 것이 좋다. (이유: 많은 자원/비용을 소모하기 때문에) - SQL문의 효율이 낮아져서 서비스 응답 시간이 느려질 수 있다.
SELECT [조회할 열1], [조회할 열2], ... , [조회할 열N]
FROM [조회할 테이블 이름]
ORDER BY [정렬기준 열 이름] [정렬 옵션(DESC or ASC)];
- DBMS = DataBase Management System - RDBMS = Relational DataBase Management System
- DBMS를 통한 데이터 관리의 장점 1. 데이터 중복을 피할 수 있다. 2. 여러 Application들이 데이터를 동시에 공유할 수 있다. 3. 각각의 Application의 데이터 관리 방식을 통일할 수 있다. 4. 각각의 Application의 업데이트 또는 변경과 관계없이 데이터를 사용할 수 있다.
- 데이터 모델의 종류 1. 계층형 데이터 모델(Hierarchical Data Model): Tree 구조를 활용 / 1960~80년대까지 많이 사용 2. 네트워크형 데이터 모델(Network Data Model): Graph 구조를 활용 3. 객체 지향형 데이터 모델(Object-oriented Data Model): 오버라이드와 같은 기능 사용 가능 / 적용이 까다로움 4. 관계형 데이터 모델(Relational Data Model): 현대에 가장 많은 데이터베이스의 바탕이 되는 모델 / 관계에 초점을 둠.
- 관계형 데이터 모델의 핵심 구성요소 3가지 1. 개체(Entity): 데이터베이스에서 데이터화하려는 사물, 개념의 정보 단위 (Table) 2. 속성(Attribute): 개체를 구성하는 데이터의 가장 작은 논리적 단위 (Column) 3. 관계(Relationship): 개체와 개체 또는 속성간의 연관성을 나타내기 위해 사용함. (외래키(Foreign Key)로 구현)
- SQL (Structured Query Language)란, RDBMS에서 데이터를 다루고 관리하는 데 사용하는 데이터베이스 질의 언어
CHAPTER 2. 관계형 데이터베이스와 오라클 데이터베이스
- 테이블(Table): 관계형 데이터베이스는 기본적으로 데이터를 2차원 표 형태로 저장하고 관리함. (= Relation) - 행(Column): 저장하려는 하나의 개체를 구성하는 여러 값을 가로로 늘어뜨린 형태 (= Tuple, Record) - 열(Row); 저장하려는 데이터를 대표하는 이름과 공동 특성을 정의 (= Attribute, Field)
- 특별한 의미를 지닌 열(Column) = 키(Key) 1. 기본키 (PK: Primary Key): 한 테이블 내에서 중복되지 않은 값만 가질 수 있는 키 (아래 3가지 조건 충족 필요) A. 테이블에 저장된 행을 식별할 수 있는 유일한 값. B. 값의 중복이 없어야 한다. C. NULL 값을 가질 수 없다.
2. 보조키 = 대체키(Alternate Key) A. 유일하면서도 NULL 값이 없어 기본키가 될 수 있는 후보키
3. 외래키(FK: Foreign Key): A. 특정 테이블에 포함되어 있으면서 다른 테이블의 기본키로 지정된 키 B. 외래키를 사용하면 여러 행에 걸쳐 특정 열을 병합하는 효과를 얻을 수 있어 데이터 중복을 최소화 할 수 있다.
4. 복합키(Composite Key): A. 여러 열을 조합하여 기본키 역할을 할 수 있게 만든 키
- 오라클 데이터베이스의 자료형 1. VARCHAR2(길이): 최대 4000byte 만큼의 가변 길이 문자열 데이터 저장 가능 (최소 1byte) 2. CHAR(길이): 최대 4000byte 만큼의 고정 길이 문자열 데이터 저장 가능 (최소 1byte) 3. NUMBER(전체자릿수, 소수점 이하 자릿수): ±38자릿수의 숫자를 저장할 수 있음. 4. DATE: 날짜 형식을 저장하기 위해 사용하는 자료형(연/월/일/시/분/초)
- 오라클 데이터베이스의 객체 1. 테이블(Table): 데이터를 저장하는 장소 2. 인덱스(Index): 테이블의 검색 효율을 높이기 위해 사용함. 3. 뷰(View): 하나 또는 여러 개의 선별된 데이터를 논리적으로 연결하여 하나의 테이블처럼 사용하게 함. 4. 시퀀스(Sequence): 일련번호를 생성해줌. 5. 시노님(Synonym): 오라클 객체의 별칭 6. 프로시저(Procedure): 프로그래밍 연산 및 기능 수행이 가능함. (Return 값 없음) 7. 함수(Function): 프로그래밍 연산 및 기능 수행이 가능함. (Return 값 있음) 8. 패키지(Package): 관련있는 프로시저와 함수를 보관함. 9. 트리거(Trigger): 데이터 관련 작업의 연결 및 방지 관련 기능을 제공함.
현재 MAC은 second notebook으로 활용중이라 코드 작성을 위해 가벼운 VS Code를 사용하고 있다. 사실 Visual Studio Code (이하 VS Code)는 IDE보다는 code(text) editor에 가깝지만.., (대부분의 운영체제에서 구동이 가능하고, 폭넓은 확장(Extension)을 제공하고 있어 많은 개발자들이 애용하고 있다.)
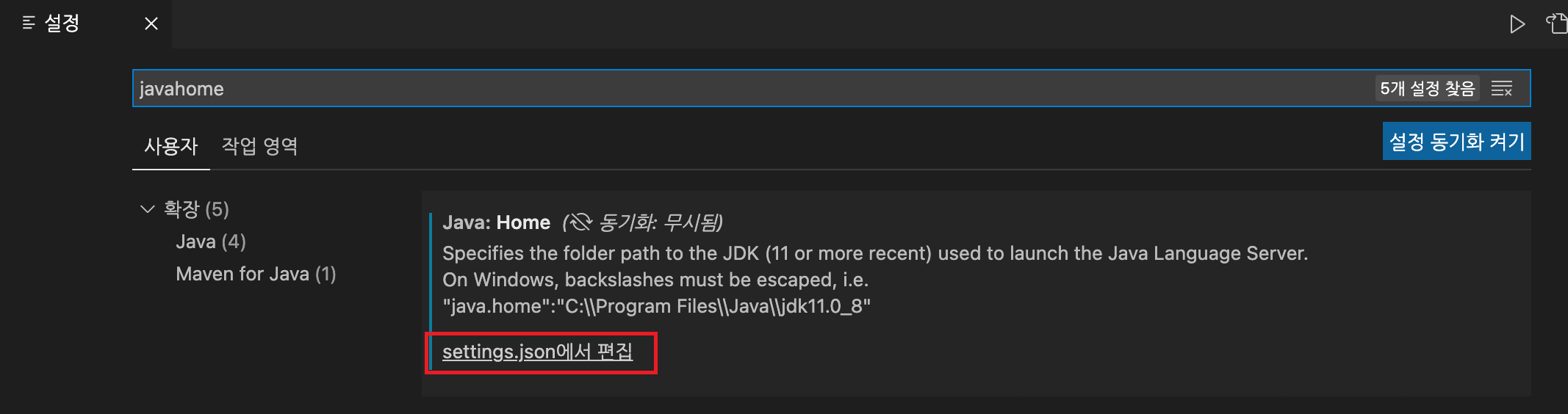
각설하고, Java를 VS code에서 사용하기 위해서는 Java 설치 및 설치 경로를 아래와 같은 과정을 거쳐 설정해주어야 한다.
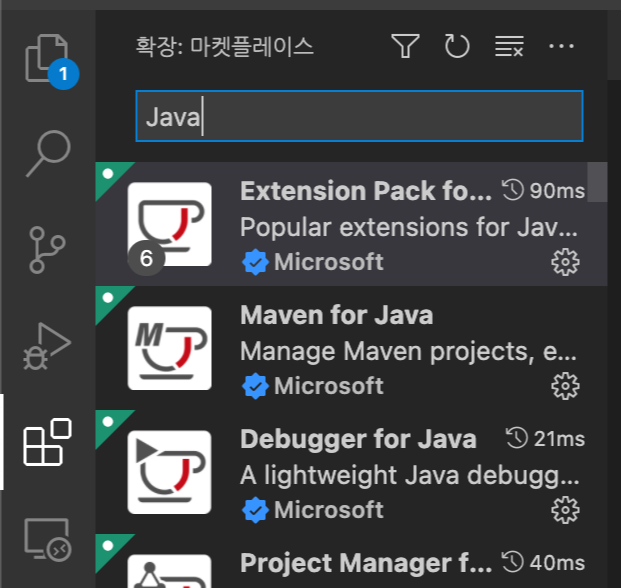
1. 확장(Extension)에서 'Extension Pack for Java' 설치
1-(1) 확장(Extension) 아이콘을 누른 뒤, 검색창에 'Java'를 검색하여 Extension Pack for Java'를 클릭
1-(2) 'Extension Pack for Java'을 설치
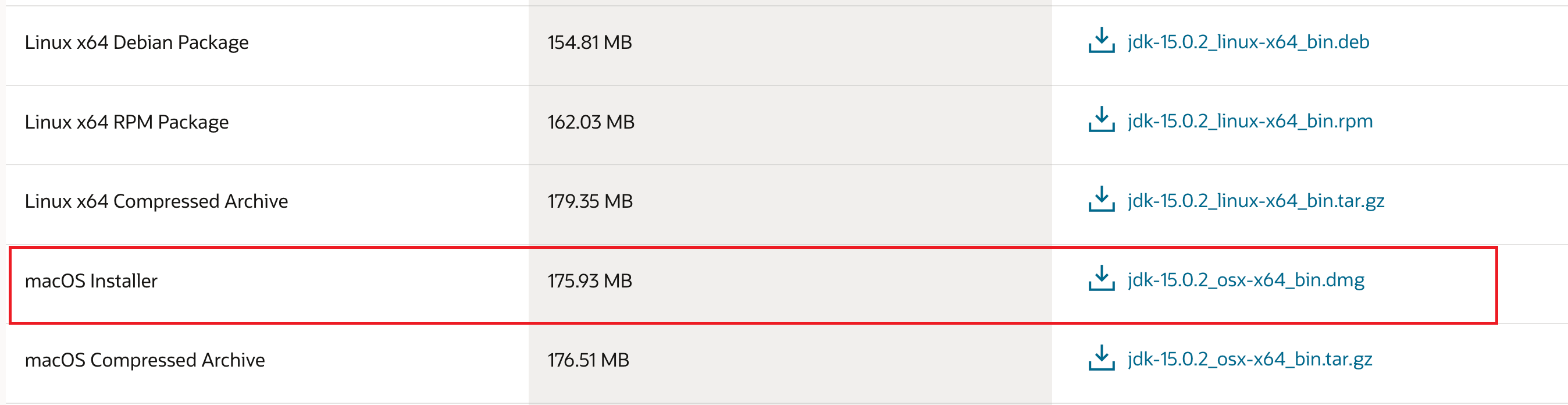
2. Java SDK (Software Development Kit) 설치
2-(1) 아래 링크에서 원하는 버젼의 Java SDK를 설치 (현재는 Java SE 18까지 나와있음.)
- 위의 코드는 굉장히 비효율적인데, 그 이유는 재귀 호출할 때마다 같은 사례를 중복 계산하기 때문이다. (ex) bin(n-1, k-1), bin(n-1, k) 모두 bin(n-2, k-1)의 계산 결과가 필요하다. - divide and conquer에서 input을 원래 크기와 별 차이 없는 크기로 분할하는 경우이기 때문에 비효율적이다.
- 이에, Dynamic Programming 기법을 사용하여 이항계수를 좀 더 효율적으로 구할 수 있다. - 이 문제를 푸는 Dynamic Programming의 재귀 관계식은 아래와 같다.
3.2 프로이드의 최단경로 알고리즘(Floyd's Algorithm for Shortest Paths)
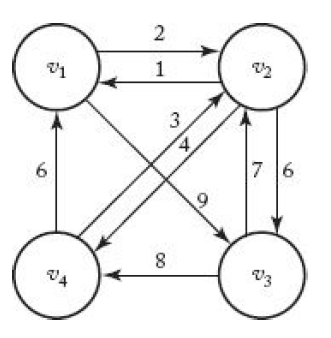
- 그래프(Graph)를 그림으로 표현하는 경우, 원은 마디(Vertex), 마디를 잇는 선은 이음선(Edge)이라고 한다. - 이음선(Edge)에 방향이 있는 그래프는 방향 그래프(Directed Graph, digraph)라고 한다. - 이음선(Edge)와 관련된 값을 가중치(weights)라고 하며, 가중치가 있는 그래프를 weighted graph라고 한다.
- 방향 그래프(Directed Graph)에서 다음 마디(Vertex)로 가는 이음선(Edge)가 있는 마디(Vetex)의 Sequence를 Path라고 하며, 어떤 마디에서 그 마디 자신으로 가는 경로는 Cycle이라고 한다. - 그래프에 Cycle이 있으면 cyclic 하다고 하며, 없는 경우에는 acyclic 하다고 한다. - 같은 마디(Vertex)를 두 번 이상 거치지 않는 경로를 simple path라고 한다. - weighted graph에서 path의 length는 path 상에 있는 weight들의 합이며, weight가 없는 graph에서는 path 상에서의 이음선(edge)의 개수이다.
- 최단 경로(Shortest Path) 문제는 최적화 문제(Optimization problem)에 속한다. - 최적화 문제에는 하나 이상의 해답 후보(Candidate solution)이 있을 수 있다. - 해답 후보에는 그와 관련된 Value가 있고, 해당 문제의 해답은 해답 후보 값들 중 최적값(Optimal value)가 된다.
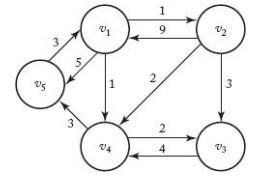
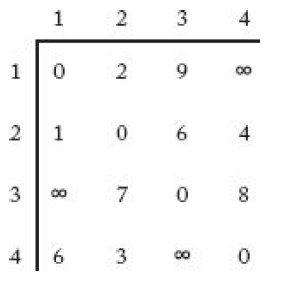
- vertex A에서 vertex B로 가는 이음선(Edge)가 있는 경우 A는 B에 인접하다(adjacent) - 인접 행렬(adjacent matrix) W는 아래와 같은 규칙에 따라 작성할 수 있다.
- 예시로 왼쪽 아래 그림의 Weighted Directed graph는 오른쪽의 adjacent matrix로 나타날 수 있다. - 최단 경로 문제를 DP(Dynamic Programming)으로 풀기 위해서는 배열 D가 필요하다. - 배열 D는 아래와 같이 작성된다.
(case 2) vertex i와 j로 가는 최단 경로가 모두 특정 vertex k를 거치는 경우 - vertex k를 무조건 거치므로, shortest_path(i, j) = shortest_path(i, k) + shortest_path(k, j)이다.
vertex i에서 vertex j까지의 최단 경로의 vertex k가 있는 경우
- 이에 case2에서는 아래 수식을 만족하게 된다. $$ {D}^{\left(k\right)}\left[i\right]\left[j\right]\ =\ D^{\left(k-1\right)}\left[i\right]\left[k\right]\ +\ {D}^{\left(k-1\right)}\left[k\right]\left[j\right] $$
- 최종적으로 배열 D를 구하는 수식은 아래와 같다. (min의 첫 번째 항은 case 1, 두 번째 항은 case 2) $$ D^{\left(k\right)}\left[i\right]\left[j\right]\ \ =\ \min _{ }^{ }\left({D}^{\left(k-1\right)}\left[i\right]\left[j\right],\ \ \ {D}^{k-1}\left[i\right]\left[k\right]\ +\ {D}^{k-1}\left[k\right]\left[j\right]\right) $$
- Floyd의 Shortest Path Algorithm code는 아래와 같다.
void floyd (int n, const number W[][], number D[][])
{
index i, j, k;
D = W;
for(k = 1; k <= n; k++)
for(i = 1; i <= n; i++)
for(j = 1; j <= n; j++)
D[i][j] = minimum(D[i][j], D[i][k] + D[k][j]);
}
- 위의 코드는 for-loop 3개가 n 번씩 돌게 되므로, 시간 복잡도 T(n)은 아래와 같이 계산된다.
3.3 동적 계획과 최적화 (Dynamic Programming and Optimizaiton Problems)
- 최적화 문제를 동적계획법(Dynamic Programming)으로 풀기 위해서는 최적의 원칙이 성립해야 한다. - 어떤 문제의 입력 사례(instance)가 그 입력 사례를 분할한 부분 사례(substances)에 대한 optimal solution을 항상 포함하고 있으면, 해당 문제는 최적의 원칙(Principle of optimality)이 성립한다고 한다. - 최적의 원칙이 성립하지 않는 예시로는, 최장 경로 문제(Longest path problem)이 있다.
3.4 연쇄 행렬 곱셈 (Chained Matrix Multiplication)
- (i * j) 행렬과 (j * k) 행렬을 곱하면 원소 단위 곱셈의 실행횟수는 (i * j * k) 번이 된다. - 6개의 행렬을 곱하는 최적의 순서는 다음의 5개 경우 중 하나이다.
- 위의 관계식을 기반으로 하여 divide and conquer 기법을 사용하면 지수 시간 알고리즘에 해당한다. - 이에 아래 그림과 같이 dynamic programming을 사용하여 좀 더 효율적으로 알고리즘을 작성할 수 있다.
Example of 'Array M'
- 최소 곱셈의 코드는 아래와 같다.
int minmult (int n, const int d[], index P[][])
{
index i, j, k, diagonal;
int M[1..n][1..n];
for(i = 1; i <= n; i++)
M[i][i] = 0;
for(diagonal = 1; diagonal <= n-1; diagonal++){
for(i = 1; i <= n-diagonal; i++){
j = i + diagonal;
for(k = i; k <= j-1; k++){
M[i][j] = minimum(M[i][k] + M[k+1][j] + d[i-1] * d[k] * d[j]);
P[i][j] = a value of k that gave the minimum;
}
}
}
return M[1][n];
}
- 최소 곱셈의 시간 복잡도는 아래와 같다. - (j = i + diagonal)이므로, k-loop 안에서 실행되는 횟수는 아래와 같다.
- 이분 검색 트리(Binary Search Tree)의 원소들을 최적으로 정리하는 알고리즘을 만들어보자. - 이진 트리(Binary)에서 어떤 마디(node)의 왼쪽[오른쪽] 자식 마디(child)를 root로 하는 하위 트리를 그 마디의 왼쪽 하위 트리(Left Subtree)[오른쪽 하위 트리(Right Subtree)]라고 한다.
* 정의
- 이분 검색 트리(Binary Search Tree)는 Ordered set으로 속한 원소로 구성된 이진 트리(Binary Tree)이다. - 이분 검색 트리는 아래와 같은 조건을 만족한다. (1) 각 마디(node)는 하나의 원소(element)만을 가지고 있다. (2) 마디의 왼쪽 하위 트리에 있는 원소들은 모두 그 마디의 원소보다 작거나 같다. (3) 마디의 오른쪽 하위 트리에 있는 원소들은 모두 그 마디의 원소보다 크거나 같다.
- 마디의 깊이(Depth of node)는 root에서 해당 node로 가는 unique path에서 edge의 개수이다. - 트리의 깊이(Depth of tree)는 해당 트리의 모든 마디의 깊이 중 최댓값을 나타낸다. - 깊이(Depth)는 때때로 수준(Level)이라고도 불린다. - 모든 마디의 두 하위 트리의 깊이가 1 이상 차이 나지 않는 트리를 balanced Tree라고 한다.
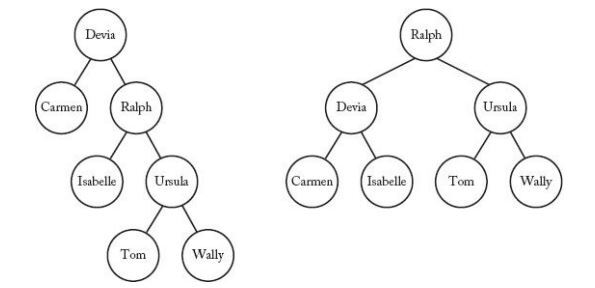
Two binary search trees
- 위 그림의 왼쪽 Tree는 Balanced Tree가 아니며, 오른쪽 Tree는 Balanced Tree이다. - Binary Search Tree에서 search key를 찾는 데 걸리는 평균 시간이 최소가 되도록 정리하는 것이 중요하며, 그렇게 정리한 Tree를 최적(Optimal)이라고 한다.
- 만약 각 원소가 search key 일 확률이 모두 같다고 하면, 오른쪽 Tree는 Optimal이다.
- Binary Search Tree에서 원소를 검색하는 코드는 아래와 같다.
struct nodetype
{
keytype key;
nodetype* left;
nodetype* right;
}
typedef nodetype* node_pointer;
void search (node_pointer tree, keytype keyin, node_pointer& p) // keyin : search key
{
bool found;
p = tree;
found = false;
while(!found){
if(p->key == keyin)
found = true;
else if(keyin < p->key)
p = p->left;
else if(keyin > p->key)
p = p->right;
}
}
- 최적 트리는 해당 트리의 left sub-tree의 최적 트리와 right sub-tree의 최적 트리를 포함한다.
A[1][k-1] : left sub-tree에서의 평균 시간 p(1) + ... + p(k-1), p(k+1) ... + p(n) : 뿌리에서 비교하는데 드는 추가시간 p(k) : 뿌리를 검색하는 평균 시간 A[k+1][n] : right sub-tree에서의 평균 시간
- 최적 이분 검색 트리(Optimal Binary Search Tree)를 구축하는 코드는 아래와 같다.
node_pointer tree (index i, j)
{
index k;
node_pointer p;
k = R[i][j];
if(k == 0)
return NULL;
else {
p = new_nodetype;
p->key = Key[k];
p->left = tree(i, k-1);
p->right = tree(k+1, j);
return p;
}
}
3.6 외판원 문제(The Traveling Salesperson Problem)
- 외판원이 20개 도시로 판매 출장을 계획하고 있으며, 각 도시는 몇 개의 도시와 도로로 연결되어 있다. - 외판원이 자신이 거주하고 있는 도시에서 출발하여 각 도시를 한 번씩 방문한 뒤, 다시 출발한 도시로 돌아오는 여행길을 찾는 문제를 외판원 문제(The Traveling Salesperson problem)이라고 한다.
- 이 문제는 도시를 마디(vertex, node)로 하여 weighted directed graph로 표현하여 문제를 해결할 수 있다.
- 일주여행길(tour)는 해밀턴 회로(Hamiltonian circuits)라고도 하며, optimal tour는 최소 거리 tour이다.
- n 개의 도시가 있고 각 도시에서 다른 도시로의 edge가 모두 존재할 때, tour의 총 가지 수는 아래와 같다.
void travel(int n, const number W[][], index P[][], number& minlength)
{
index i, j, k;
number D[1..n][subnet of V-{v(1)}];
for(i=2; i<=n; i++)
D[i][empty] = W[i][1];
for(k=1; k<=n-2; k++){
for(all subnet A containing k vertices){
for(i such that i!= 1 and v(i) is not in A){
D[i][A] = min(W[i][j] + D[i][A - {v(j)}]);
P[i][A] = value of j that gave the minimum;
}
}
}
D[1][V - {v(1)}] = min(W[1][j] + D[j][V-{v(1), v(j)}]);
P[1][V - {v(1)}] = value of j taht gave the minimum;
min length = D[1][V - {v(1)});
}
- 최악 시간 복잡도(Worst-case Time Complexity)가 지수 시간보다 좋은 외판원 문제를 푸는 알고리즘은 없다. - 하지만, 지수 시간보다 좋은 알고리즘이 없다고 증명한 사람도 존재하지 않는다.
3.7 DNA 서열 정렬(Sequence Alignment)
- DNA는 A, G, C, T 4개의 염기로 구성되어 있으며, (A, T)와 (G, C)가 쌍을 이룬다. - 동족서열이 아래와 같을 때,
A A C A G T T A C C
T A A G G T C A
틈(gap)의 cost를 1, 불일치(mismatch)의 cost를 3으로 두면,
_ A A C A G T T A C C
T A A _ G G T _ _ C A
인 경우에는 정렬에 드는 cost가 10(1 + 1 + 3 + 1 + 1 + 3)이다.
A A C A G T T A C C
T A _ A G G T _ C A
인 경우에는 정렬에 드는 cost가 11(3 + 1 + 3 + 1 + 3)이다.
- 최적 정렬(Optimal alignment)를 구하기 위한 계산은 아래 3가지 경우 중 하나로 시작해야 한다. (1) x[0]과 y[0]을 맞추어 정렬한다. x[0] = y[0]이면, 첫 alignment site에서는 peantly가 없고, x[0] != y[0]이면 penalty가 1이다.
(2) x[0]과 gap을 맞추어 정렬하고, 첫 alignment site에서 peanlty가 2이다.
(3) y[0]과 gap을 맞추어 정렬하고, 첫 alignment site에서 penalty가 2이다.
- DNA 서열 정렬을 위해 divide and conquer 방법을 사용하면 코드는 아래와 같다.
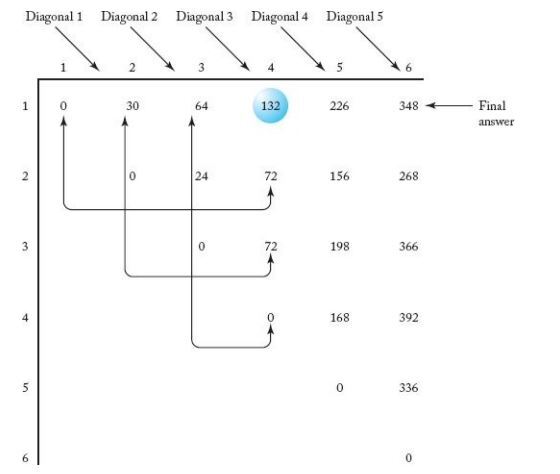
- 위의 divide and conquer 방법을 사용하면 중복 계산되는 항들이 많아지게 되어 비효율적이게 된다. - 이에 배열을 사용하여 아래와 같이 구해볼 수 있다. - Diagonal1, Diagonal2, ... 로 계산을 수행해가며, 최종 답인 cost 값은 [0][0]에 저장되게 된다.
- 위 배열에서 어떻게 [0][0] 값을 계산했는지 경로를 추적할 수 있다.
(1) [0][0]을 선택한다. (2) 경로에 넣을 둘째 항목을 찾는다. (a) [0][1]을 검사한다. (b) [1][0]을 검사한다. (c) [1][1]을 검사한다.
- 경로를 찾으면, 정렬된 서열(alignmented sequence)를 다음과 같이 추출할 수 있다.
(1) 배열의 오른쪽 맨 아래부터 시작하여 표시해둔 경로를 따라간다. (2) 배열의 [i][j] 칸에 도달하기 위해서 대각선으로 이동할 때마다, i 번째 항에 해당하는 문자를 x에 넣고, j 번째 열에 해당하는 문자를 y 서열에 넣는다. (3) 배열의 [i][j] 칸에 도달하기 위해서 위로 이동할 때마다, i 번째 항에 해당하는 문자를 x 서열에 넣고, 틈 문자(gap)을 y 서열에 넣는다. (4) 배열의 [i][j] 칸에 도달하기 위해서 왼쪽으로 이동할 때마다, j 번째 행에 해당하는 문자를 y 서열에 넣고, 틈 문자(gap)을 x 서열에 넣는다.
-Reference- Neapolitan, Richard E., 『Foundation of algorithms FIFTH EDITION』
- 문제의 입력를 두 개 이상의 작은 입력으로 나누고, 답을 얻기 위해 시도한다. - 답을 얻지 못했다면, 또 각각의 입력 사례에 대해 분할을 한 뒤, 다시 시도한다. - Divide and Conquer는 하향식(Top-Down) 방식의 접근법이다.
2.1 이분검색 (Binary Search)
- 이분 검색 알고리즘은 오름차순으로 정렬된 배열에서 실행가능하며, 수행 절차는 아래와 같다.
1. [Divide] 배열을 정 가운데 원소를 기준으로 반으로 분할한다. 찾고자 하는 수 x가 가운데 원소보다 작으면 왼쪽 배열을 선택한다. x가 가운데 원소보다 크면 오른쪽 배열을 선택한다. 2. [Conquer] 선택한 반쪽 배열을 정복한다. 즉, 선택한 반쪽 배열에 x가 있는지 재귀적으로 이분검색한다. 3. [Obtain] 선택한 반쪽 배열에서 얻은 답이 최종 답이다.
1. [Divide] 배열을 반으로 분할한다. (분할한 배열의 원소는 각각 n/2개 이다.) 2. [Conquer] 분할한 배열을 각각 따로 정렬한다. 3. [Obtain] 정렬한 두 배열을 합병하여 정렬한다.
void mergesort(int n, keytype S[])
{
if(n > 1) {
const int h = [n/2], m = n-h;
keytype U[1..h], V[1..m];
copy S[1] through S[h] to U[1] through U[h];
copy S[h+1] through S[n] to V[1] through V[m];
mergesort(h, U);
mergesort(m, V);
merge(h, m, U, V, S);
}
}
void merge(int h, int m, const keytype U[], const keytype V[], keytype S[])
{
index i, j, k;
i = 1; j = 1; k = 1;
while( i <= h && j <= m) {
if(U[i] < V[j]) {
S[k] = U[i];
i++;
}
else {
S[k] = V[j];
j++;
}
k++;
}
if(i > h)
copy V[j] through V[m] to S[k] through S[h+m];
else
copy U[i] through U[h] to S[k] through S[h+m];
}
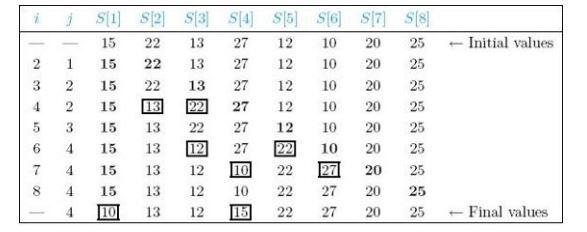
The steps when searching with Merge Sort
- Merge의 Worst-case Time Complexity W(h,m)은 아래와 같다. (두 배열 U,V의 원소 개수는 h, m이다.)
$$ W\left(h,m\right)\ =\ h\ +\ m\ -\ 1 $$
- Mergesort의 Worst-case Time Complexity W(n)은 아래와 같다.
이므로, 실용적으로 사용하기 힘들다. 이에 Strassen은 곱셈을 기준으로 하든, 덧셈/뺄셈을 기준으로 하든지에 상관없이 시간복잡도가 3차보다 좋은 알고리즘을 발표하였다.
The partitioning into submatrics in Strassen's Algorithm
void strassen(int n, nxn_matrix A, nxn_matrix B, nxn_matrix& C)
{
if(n <= threshold)
compute C = A X B using the standard Algorithm.
else {
partition A into four matrices A11, A12, A21, A22;
partition B into four matrices B11, B12, B21, B22;
compute C = A X B using Strassen's method;
// example recursive call;
// strassen(n/2, A11 + A22, B11 + B22, M1);
}
}